概述
什么是模型微调?
模型微调是通过微调工具,使用独特的场景数据对平台的基础模型进行调整,帮助您快速定制一个更符合业务需求的大型模型。其优势在于对基础模型进行小幅调整以满足特定需求,相比于训练一个新模型,这种方法更为高效且成本更低。何时适用微调?
您可以首先尝试调整提示或使用函数调用和检索功能等工具来改善结果。如果您发现基础模型及相关工具仍无法提供满意的答案或处理复杂的推理任务,则可以使用微调来获得更好的结果。 微调可以改善结果的典型场景包括:- 需要特定的风格或语气
- 需要处理复杂任务
- 需要提高输出可靠性
- 新任务难以通过提示解释
有哪些微调方式?
SFT:训练后提升模型的指令遵循能力。 DPO:训练后模型输出内容更符合用户偏好。有哪些训练方式?
LoRA 微调
- 含义: 通过在现有权重矩阵中添加低秩矩阵来调整模型,可以在增加少量计算负担的情况下有效调整模型。
- 优势: 仅增加少量参数,参数效率高; 资源利用少,训练周期短
全参数微调
- 含义: 调整预训练模型的所有参数以获得新模型。
- 优势: 允许对模型进行全面调整,更好地适应新任务; 在有足够数据和计算资源的情况下,更有可能达到最佳性能。
哪些模型可以进行微调?
glm-4.5(32k上下文版本,支持 LoRA 微调,所有用户可用)glm-4.5(16k上下文版本,支持全参数微调,所有用户可用)glm-4.5-Air(支持全参数微调,所有用户可用)glm-4-0520(支持 LoRA 微调、全参数微调,云端私有化年套餐用户可用)glm-4-air-250414(支持全参数微调,所有用户可用)glm-4-flash(支持 LoRA 微调、全参数微调,所有用户可用)glm-4-9b(支持 LoRA 微调、全参数微调,所有用户可用)chatglm3-6b(支持 LoRA 微调,所有用户可用)cogview-3(支持全参微调,所有用户可用)glm-4v(支持 LoRA 微调,所有用户可用)
glm-4-flash 的 LoRA 微调训练和推理。
微调步骤
通常,完成模型微调包括以下步骤:- 准备并上传训练数据
- 训练新的微调模型
- 部署并使用微调模型(仅文生文模型 LoRA 微调后支持公有池推理,其他情况均需部署后推理使用。)
- 评估结果,如有必要,返回步骤1
1. 准备训练数据
微调训练数据通常由一批包含输入和预期输出的数据组成,每条训练数据包含一个输入(Prompt)及其对应的预期输出。目前仅支持 JSON 格式文件上传训练数据。数据集要求
一般来说,提供更多高质量的训练数据会得到更好的微调效果。反之,如果训练数据存在问题或缺陷,将会对微调结果产生负面影响。 更多高质量数据: 为了更好地微调模型,您需要提供至少数百条高质量的训练数据;最好由人工严格审核数据,以确保数据质量和微调结果。增加高质量的训练数据是改善微调结果的最佳且最可靠的方法。 根据训练目标调整数据分布: 在构建训练数据时,您需要根据实际业务场景的训练目标,注意构建和调整各类细分任务场景的训练数据分布,并尽量覆盖业务场景中所有可能的数据样本。如果您的训练目标是同时提升文本分类、信息抽取和文本生成的效果,您需要在训练数据中为这些类型的任务提供足够的训练数据。 避免有害数据: 为了确保您的数据隐私,平台不会审核您的数据。请确保您的数据不包含有害信息,包括但不限于色情、恐怖主义、政治敏感、低俗辱骂、隐私信息等。使用有害数据进行微调可能会导致微调后的模型容易生成有害内容,降低模型推理结果中敏感信息验证的通过率。更糟糕的是,一个严重有害的模型可能无法通过平台或相关监管机构的内容合规要求,并会被强制从平台移除。数据集格式
大语言模型-SFT训练- 数据集分类-文本生成
- 数据集分类-文本生成(函数调用)
glm-4.5-air、glm-4-air、glm-4-flash、glm-4-9b 模型全参微调支持该格式训练。 若您希望微调函数调用能力,可用以下版本训练格式。注意,示例为结构清晰按如下展示,数据上传时需以 JSON 格式每行一条,存储在文件中并通过文件管理接口上传文件:
- 数据集分类-文本生成(深度思考)
glm-4.5-air模型全参微调支持该格式训练,若您希望微调函数调用能力,可用以下版本训练格式。注意,示例为结构清晰按如下展示,数据上传时需以 JSON 格式每行一条,存储在文件中并通过文件管理接口上传文件:
- 数据集分类-文本生成(偏好对齐)
- 数据集分类-图像生成(单图)
- Http URL
- Base 64
- 数据集分类-图像理解(单图)
注意,示例为结构清晰按如下展示,数据上传时需以 JSON 格式每行一条,存储在文件中并通过文件管理接口上传文件:
- Http URL
- Base 64
数据集上传
入口1:微调数据页面 根据您需要微调的场景,目前可以选择数据集分类为大语言模型 (chat) 训练数据、大语言模型 (function 能力) 训练数据。 入口2:微调任务创建
您也可以直接在微调任务创建时选择上传新数据集,提交的数据集会自动更新到您的「微调数据」内
入口2:微调任务创建
您也可以直接在微调任务创建时选择上传新数据集,提交的数据集会自动更新到您的「微调数据」内
2. 创建微调任务
如果您已经按照上述要求准备好了高质量的训练数据,现在可以创建微调任务来训练模型了。 您可以通过页面操作创建微调任务,入口如下:
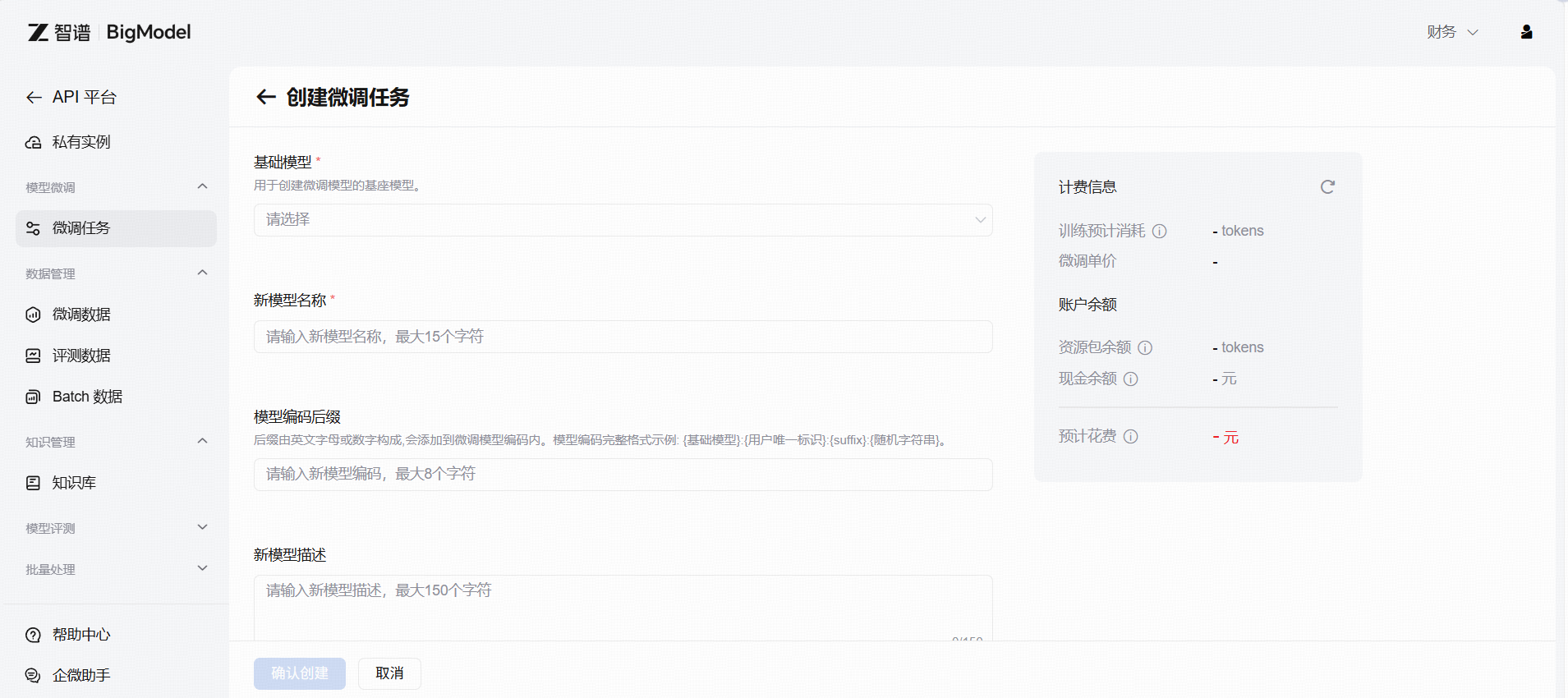 创建微调任务时,您可以根据需要命名新模型并指定模型代码的后缀。其他参数设置请参考微调API接口文档。创建微调任务后,训练完成需要几分钟到几小时不等,具体取决于模型大小和数据集大小。我们会在训练完成后通过短信通知您。
创建微调任务时,您可以根据需要命名新模型并指定模型代码的后缀。其他参数设置请参考微调API接口文档。创建微调任务后,训练完成需要几分钟到几小时不等,具体取决于模型大小和数据集大小。我们会在训练完成后通过短信通知您。
3. 部署微调模型
模型部署入口:
私有实例 点击“创建部署任务”按钮,选择要部署的基础模型/微调模型。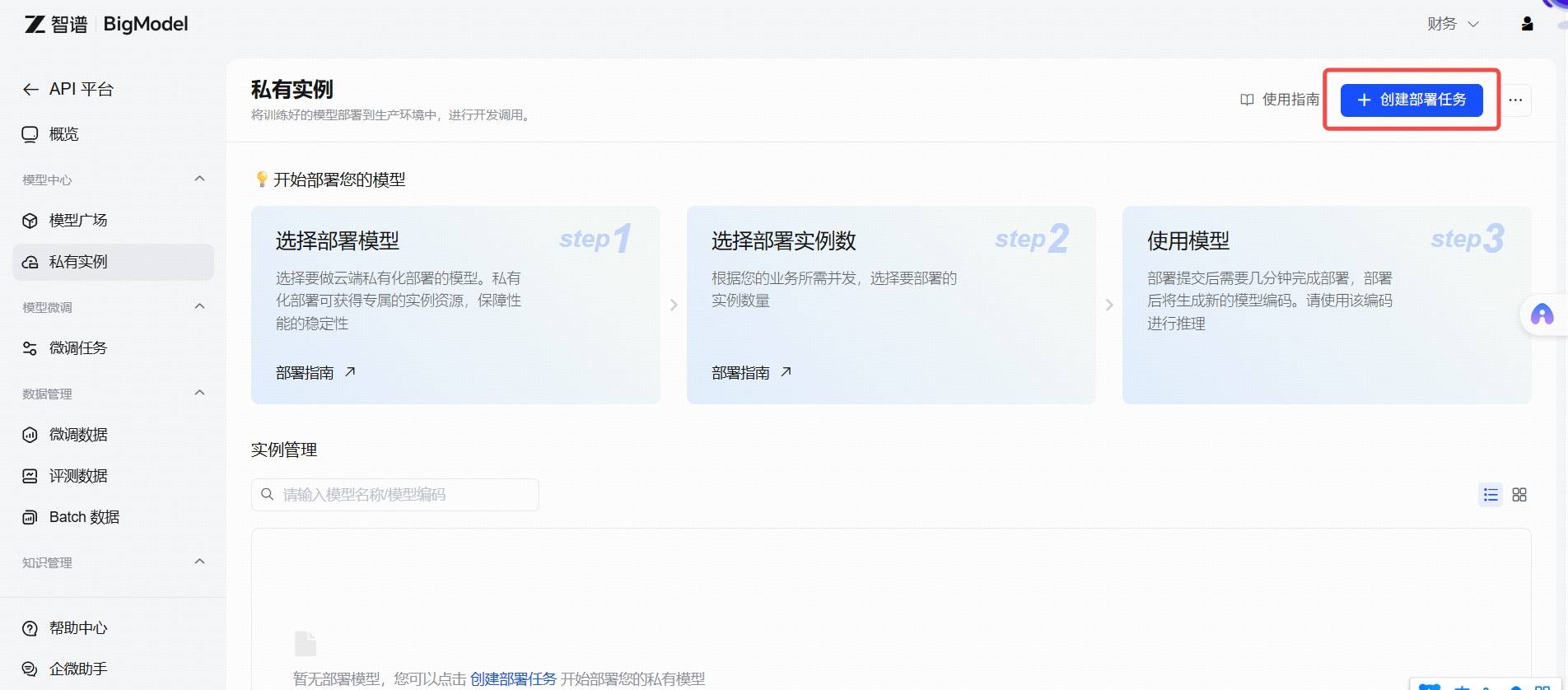
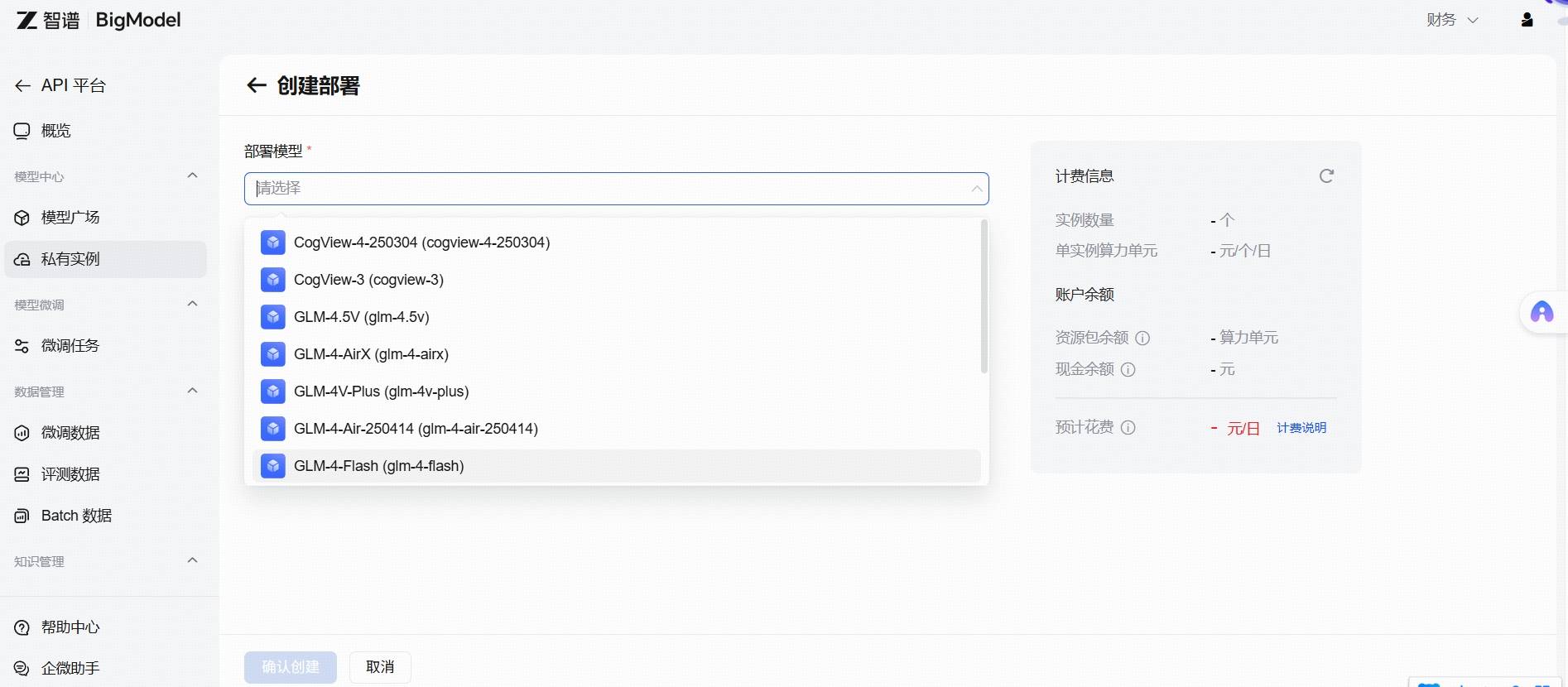 您可以根据实际使用场景的并发需求选择部署实例的数量。实例部署需要一定时间(通常为10-30 分钟,具体取决于模型大小)。我们会在部署完成后通过短信通知您。新部署的模型的模型编码、状态及实例信息可在私有实例 页面或模型广场 的模型详情页部署信息查看。
您可以根据实际使用场景的并发需求选择部署实例的数量。实例部署需要一定时间(通常为10-30 分钟,具体取决于模型大小)。我们会在部署完成后通过短信通知您。新部署的模型的模型编码、状态及实例信息可在私有实例 页面或模型广场 的模型详情页部署信息查看。
模型实例变更与取消部署
- 注意:取消部署动作将在操作后立即生效,取消后该部署模型无法再进行调用。


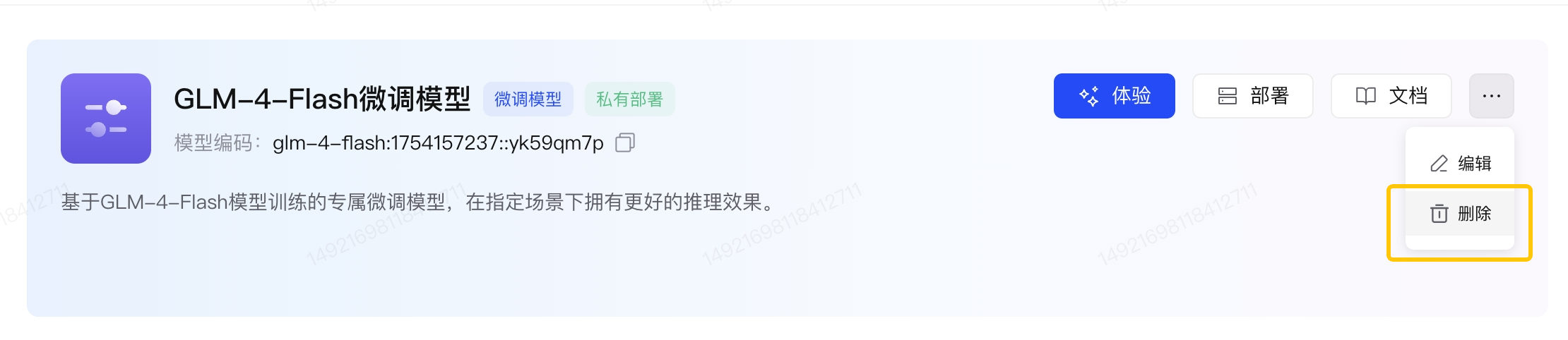
- 模型卡片删除
- 当点击模型卡片「删除」按键后,该微调模型及基于该模型部署的模型将均被删除,无法调用。
4. 模型推理
1.模型编码获取 可公有池推理的模型可以直接复制模型编码,您也可以选择在测试效果后进行私有实例部署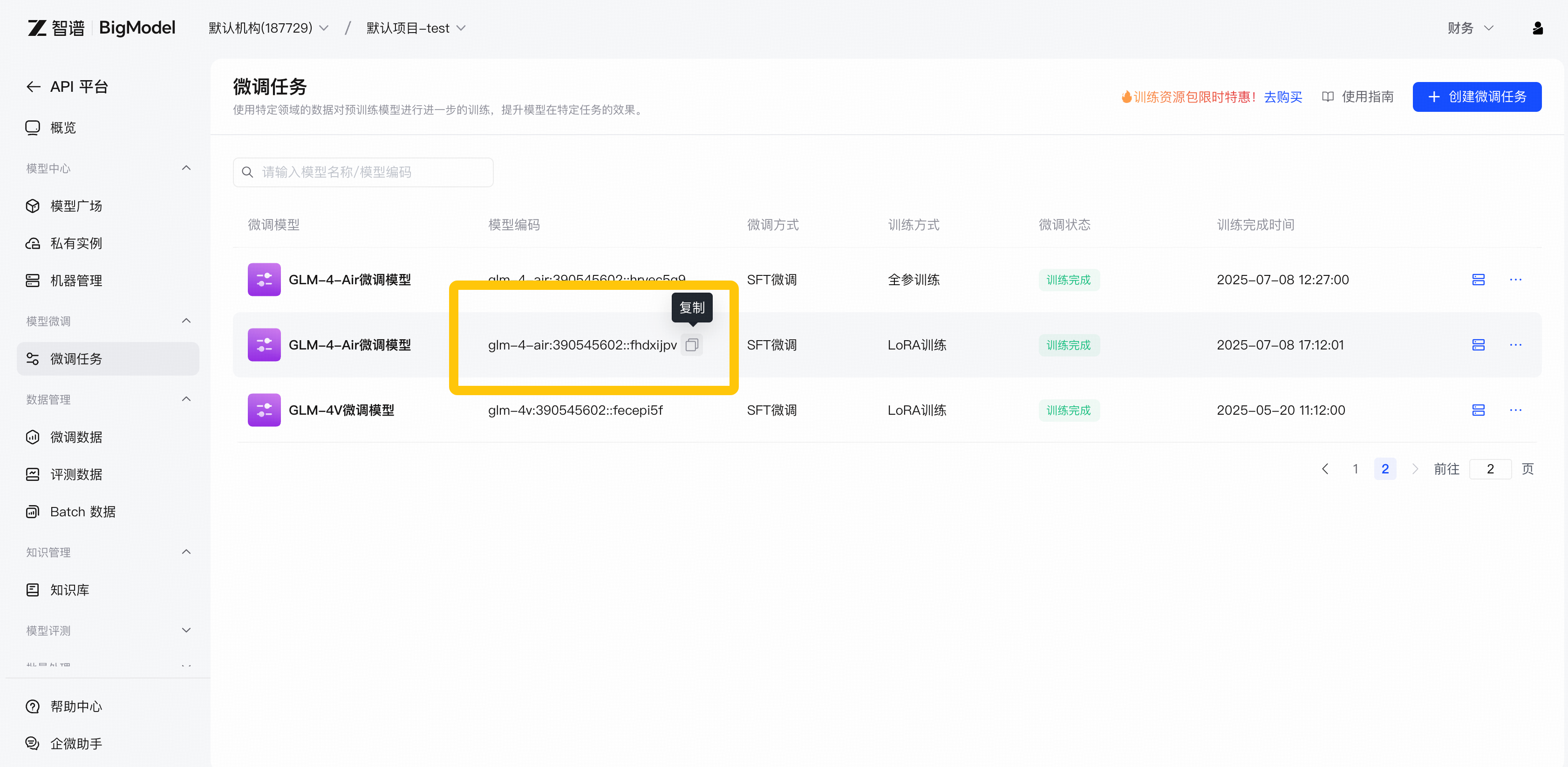 需要私有部署后推理的模型需要在部署后进行调用。部署后的编码请在模型广场对应模型卡片详情内或私有实例页面查看
需要私有部署后推理的模型需要在部署后进行调用。部署后的编码请在模型广场对应模型卡片详情内或私有实例页面查看
- 模型调用
您可以通过体验中心或 API 使用模型。在进行 API 请求时,您可以将您命名的新的模型代码作为
model参数的值传递。
调用示例
安装 SDK5. 微调训练计费说明
模型分类
- 文本模型:
- 文生图模型:
- 每张图片固定转换为 1024 Tokens
- 视觉理解模型:
-
glm-4v-plus / glm-4v-plus-0111:
- 单图 Token 固定为 2304
-
glm-4v / glm-4v-flash:
- 单图 Token 固定为 1600