概述
什么是模型评测?
模型评测(Model Evaluation)是指对人工智能或机器学习模型的性能进行系统性测量和分析的过程。评测的目标是衡量模型的准确性、效率、鲁棒性、公平性等量化指标,以确保其在实际应用中达到预期效果。常见的评测指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1-score、AUC-ROC,以及针对大模型的困惑度(Perplexity)、多样性(Diversity)、推理速度(Inference Speed)等。此外,大模型评测还可能涉及对抗性测试、偏见检测以及人类偏好对齐(RLHF)等方面。
何时使用模型评测?
模型评测通常在以下情况下使用:- 模型接入应用场景:已有应用场景,需要进行模型选型,对比多个模型效果,评测可以帮助决策,确保选用了当前应用场景最好的模型。
- 模型训练后验证:在模型训练完成后,需要评估其在测试集上的表现,以判断是否达到了可接受的标准。
- 模型优化与调优:通过对不同版本的模型进行对比评测,找到最优的参数配置、架构或训练方法。
- 模型上线前的质量控制:在模型部署到生产环境之前,进行严格评测,确保其稳定性、安全性和公平性。
- 模型迭代与版本更新:每次模型更新或新特性加入后,需要评估其相较于旧版本的改进或可能存在的问题。
支持哪些评测方法?
智谱开放平台目前支持以下两种自动评测方式:AI 裁判员自动评测和基线评测。- AI 裁判员自动评测:全程无需人工参与,将基于自定义的评测指标,通过 AI 裁判员模型对模型输出效果进行自动打分。该方式具有高效、和公正性的优势,但评测结果高度依赖人为设定的评分维度和标准。该方法适用于在特定业务场景下进行模型比选。
- 基线评测:通过预制的基线评测集对模型的各项基础能力进行自动评测,包括 GSM8k, C-Eval, MMLU 等主流评测集。该方法适用于对微调模型的基本效果进行评价,以避免模型的通用泛化能力发生明显下降。
哪些模型可以评测?
当前评测3类模型:- 智谱开放平台上所有的语言模型:GLM-4-Plus、GLM-4-0520、GLM-4-Long、GLM-4-Air、GLM-4-Flash、GLM-4-Zero-Preview 等;
- 微调后的语言模型:语言模型通过数据进行微调后的模型;
- 私有实例:云私私有化部署的语言模型;
包含哪些评测数据集和模板?
- AI 裁判员打分
- 打分指令(prompt)
- 场景评测模板
翻译场景
数据提取场景
内容创作场景
- 基线评测
评测步骤
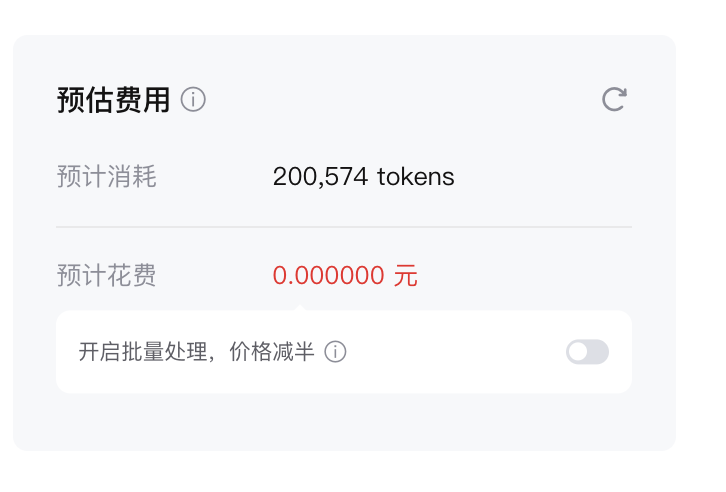
模型评测计费说明
费用均使用【通用推理】模型价格,适用于评测集推理和AI裁判员评测指令两部分,创建评测任务时会预计算【任务消耗】和【任务价格】,前3 次评测免费;模型推理价格见产品计费通用模型计费板块,Batch的批量处理功能可以和评测工具叠加使用。
创建评测任务
您可以通过页面操作来创建评测任务,入口如下: 点击“创建评测任务”按钮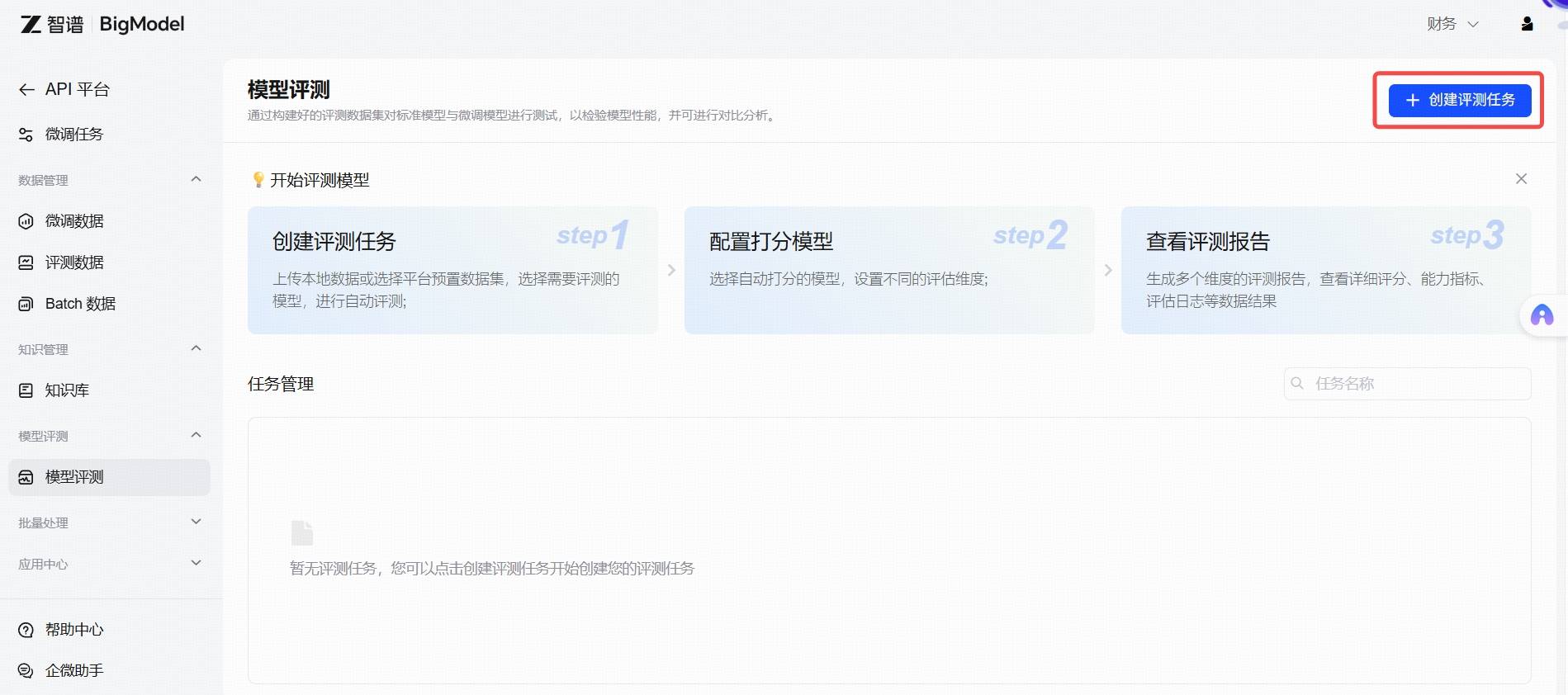
选择评测方式
智谱开放平台目前支持两种评测方式:AI 裁判员自动评测和基线评测。-
评测方式一:基线评测
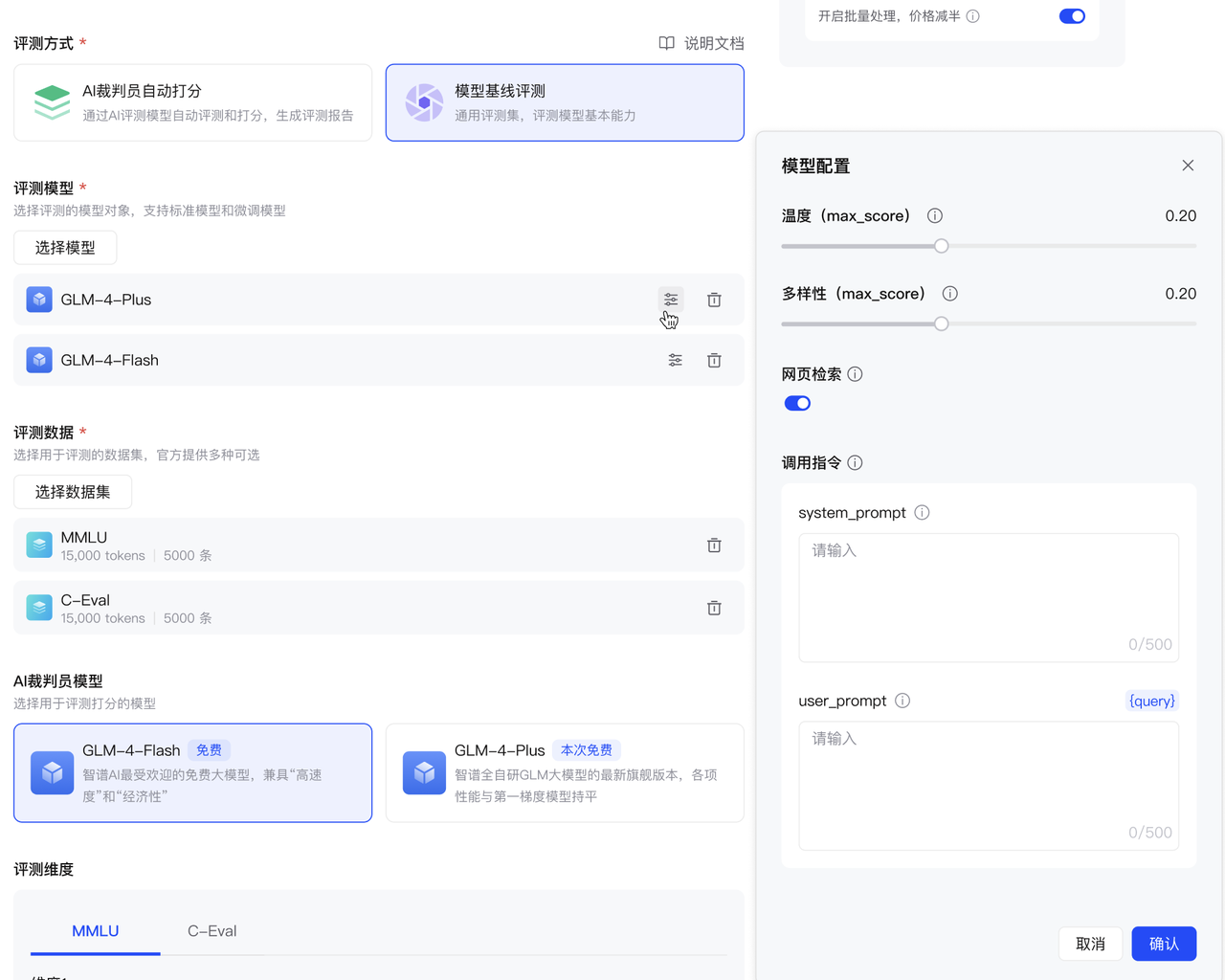
- 从评测模型列表中选择参评的模型 基线评测可选基础模型、私有化模型、微调模型。 支持同时选择多个模型。 模型配置:提供温度、多样性、网页检索、调用指令选择被评测的模型对象,支持标准模型和微调模型。
- 温度:采样温度可以控制输出的随机性。取值范围为 [0.0,1.0] ,其中值越大,输出内容将更加随机和富有创造性;值越小,输出会更加稳定或确定。
- 多样性:通过核取样(Top-p Sampling)调节模型输出的多样性。取值范围为 [0.0, 1.0],表示模型在生成时仅考虑概率质量累积达到 top_p 的候选集。例如,当值为 0.1 时,解码器只从前 10% 累积概率的候选tokens中进行选择。若 top_p 设置为 0,则此参数不生效。
- 网页检索:打开后推理自动调用web_search进行评测。
- system_prompt:系统调用指令。
- user_prompt:用户指令,可配置动态参数。
- query:为评测集中的用户问题,可作为动态参数配置在user_prompt中。
- 设置评测数据集:提供学科、数学、推理类的标准榜单(相应的评测集、评测逻辑、评测脚本与开源榜单数据保持一致,定期更新)。
- 选择AI裁判员模型
可选择glm-4-flash(免费)或glm-4-plus(旗舰)作为裁判员模型进行模型打分。
- 评测方式二:AI裁判员自动打分
- 从评测模型列表中选择参评的模型
基线评测可选基础模型、私有化模型、微调模型。
支持同时选择多个模型。
模型配置:提供温度、多样性、网页检索、调用指令选择被评测的模型对象,支持标准模型和微调模型。
- 温度:采样温度可以控制输出的随机性。取值范围为 [0.0,1.0] ,其中值越大,输出内容将更加随机和富有创造性;值越小,输出会更加稳定或确定。
- 多样性:通过核取样(Top-p Sampling)调节模型输出的多样性。取值范围为 [0.0, 1.0],表示模型在生成时仅考虑概率质量累积达到 top_p 的候选集。例如,当值为 0.1 时,解码器只从前 10% 累积概率的候选tokens中进行选择。若 top_p 设置为 0,则此参数不生效。
- 网页检索:打开后推理自动调用web_search进行评测。
- system_prompt:系统调用指令。
- user_prompt:用户指令,可配置动态参数。
- query:为评测集中的用户问题,可作为动态参数配置在user_prompt中。
- 设置评测数据集
您可以选择平台内置数据集或上传新数据集。
- 预制数据集:预制数据集目前提供了翻译、数据提取、内容创作三个场景下的评测数据集,预制数据集说明如下
- 翻译场景:将给定文本翻译成另一种语言。
- 数据抽取场景:阅读材料并完成信息提取、摘要生成、问题回答等任务。
- 内容创作场景:根据用户指定的主题、风格、体裁和目标受众,创作内容。
- 上传数据集格式:上传新数据集则需要如下规范
评测数据集需按照xlsx格式进行上传,数据包含用户问题“question”和参考答案ref_answer两个字段。
-
选择AI裁判员模型
可选择glm-4-flash(免费)或glm-4-plus(旗舰)作为裁判员模型进行模型打分。前者适合简单任务,速度更快;后者适合复杂任务,推理能力较强,但是成本较高。 -
配置评测指令
AI裁判员模型将基于评测指令对参评模型的回答进行打分。为确保不同场景下的评测结果符合您的业务要求,建议根据您的评测场景目标设置对应的评测场景、场景描述、评测维度名称、分值标准等动态变量。您可以前往模型体验中心对您的评测指令进行验证。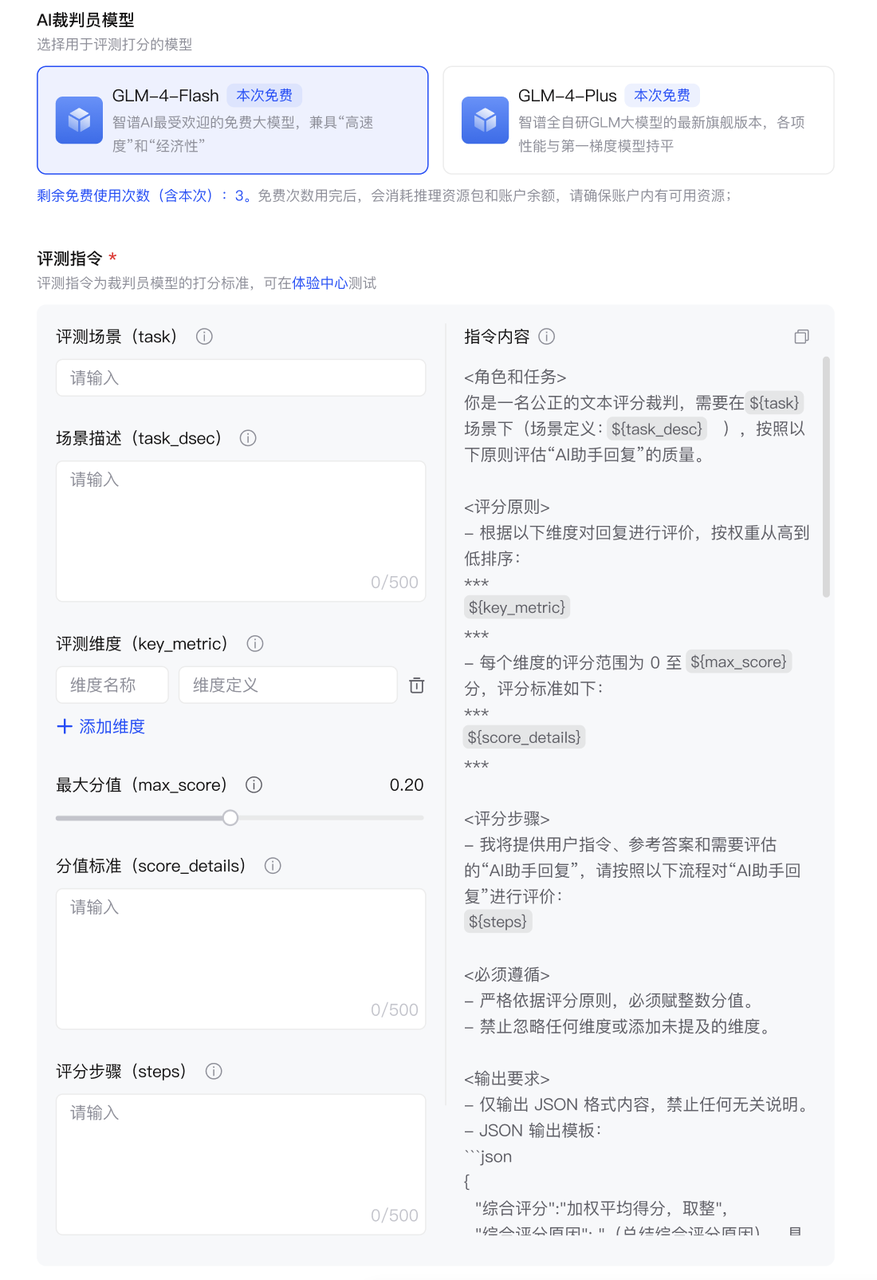
查看评测结果
查看评测状态
查看评测详情结果
在模型评测页面,当任务的评测状态为完成时,单击操作列的结果查看当前评测的任务信息及评测结果(区分为AI裁判员打分和基线评测两种评测方式)。在评测详情页(如下图所示),您可以:
- 查看当前自动评测任务的评测模型、评测方式、AI裁判员模型器、评测指令(如果是进行AI裁判员自动打分)、评测数据集情况(包含题目总量、已完成量和失败量)、消耗tokens、优惠情况、实际费用。
- 查看所有参评模型的模型名称、以及各自的评测结果报告。
- 将当前评测任务的详细结果列表下载到本地(xlsx格式)。
-
评测结果:AI裁判员打分
查看评测指令
您可以查看当前评测的评测指令Prompt。点击评测指令右侧的查看,可以展开完整的评测指令。
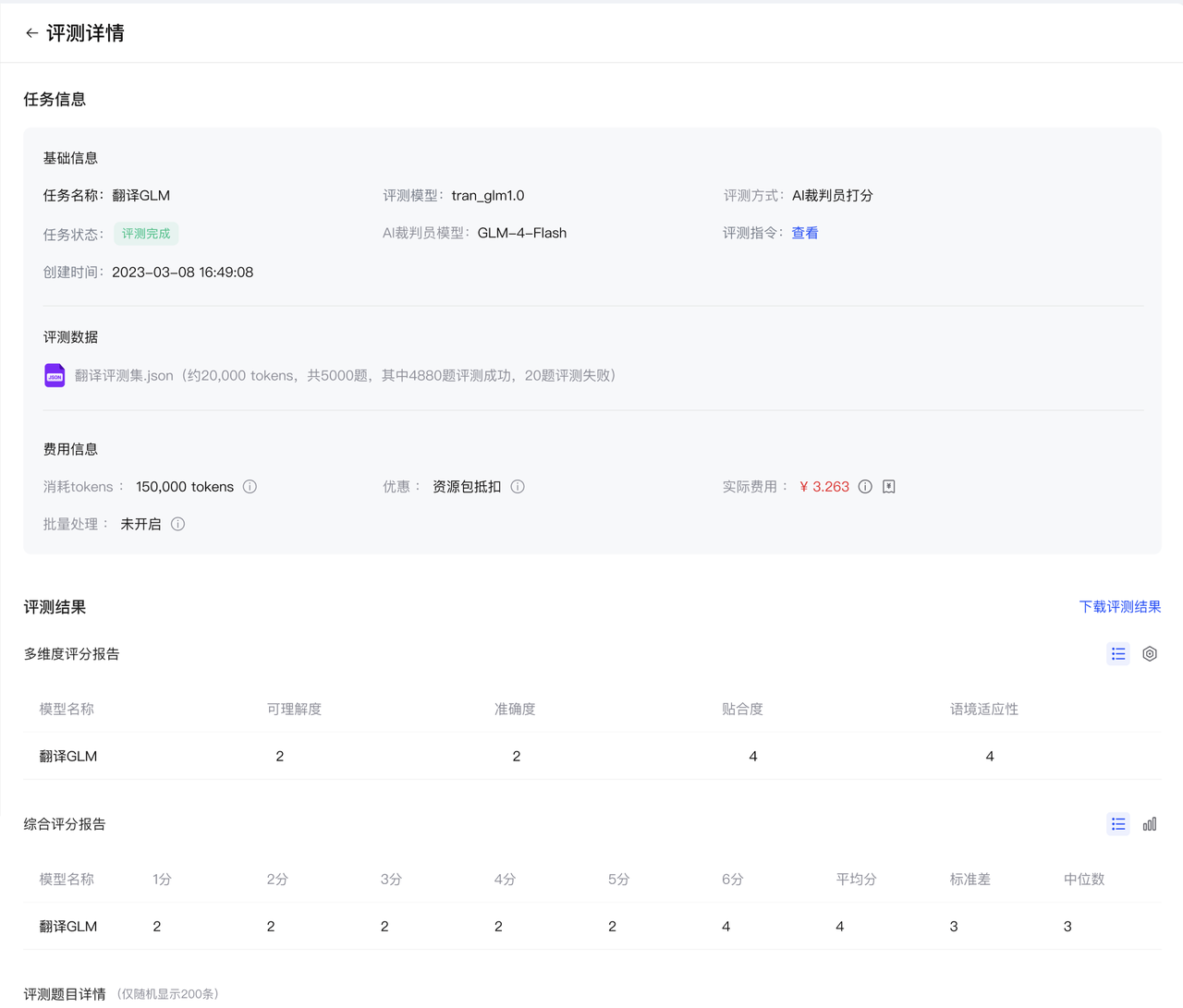 在评测结果栏(如下图所示),您可以:
在评测结果栏(如下图所示),您可以:
- 直接下载评测结果报告。
- 查看多维度评分报告和综合评分报告。
- 点击表格右侧的图标切换表格/图。
-
点击评测题目右侧的红色感叹号查看该题目评测失败原因。

-
在评测题目详情列表,可以随机显示不超过 200 条的评测题目,点击详情列中的查看,可以查看该题目的模型回复结果、评测得分以及评分原因(如下图所示)。点击对应模型得分右侧的原因,可查看完整的评分理由。

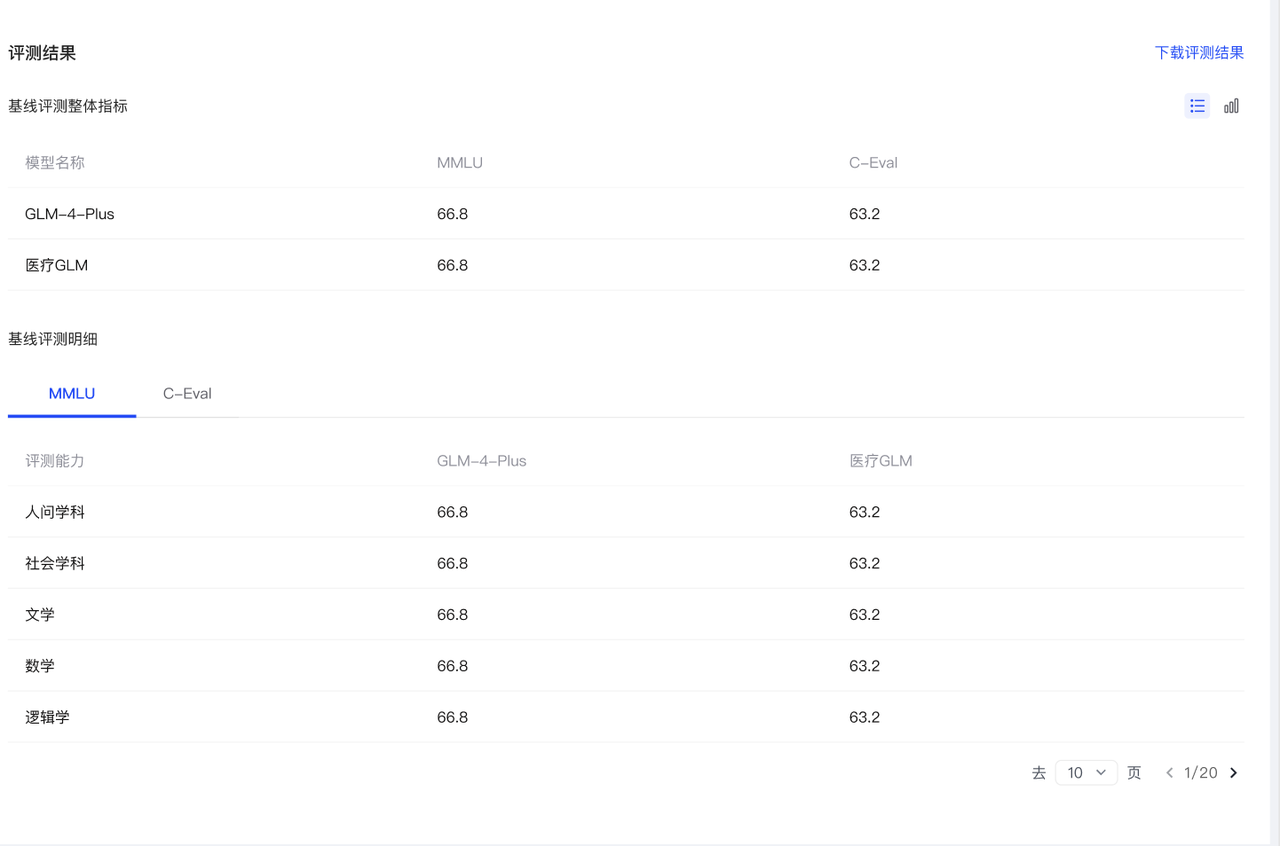
- 查看基线评测整体指标,查看基线评测基于当前基线评测集榜单的评分结果。
- 查看基线评测明细(目前仅C-Eval 和 MMLU 支持展示),展示该评测集内的不同学科维度的得分明细。
下一步建议
- 如果您对被评测模型的评测结果,即可开始在您的任务中调用模型。
- 如果对评测结果不满意,可以选择其他模型重新评测,或者根据评测的结果明确优化方式。
- Prompt提示词工程优化的成本明显低于模型微调。您可以在智谱开放平台的prompt工程最佳实践中学习相关知识。
- 如果模型频繁出现输出结果严重偏离参考答案的问题,建议您考虑引入知识库。