Documentation Index
Fetch the complete documentation index at: https://docs.bigmodel.cn/llms.txt
Use this file to discover all available pages before exploring further.
概述
📘 知识库是为大模型提供外部知识支撑的核心组件。
通过上传企业文档、网页或结构化数据,系统自动完成 解析 → 切片 → 向量化 → 上下文增强 → 检索索引,
让模型在回答问题时引用真实资料,而不仅依赖内部记忆。📋 核心价值:
- 提升回答准确性与专业度
- 降低模型幻觉风险
- 支撑企业级知识问答、FAQ、客服系统、产品文档中心、研发资料库等场景
功能特性
- 多源知识接入:支持多种文档格式和数据源
- 智能内容切片:自动拆解为语义完整的知识单元
- 高效语义向量化:精准捕捉深层语义信息
- 自动索引构建:毫秒级检索响应速度
- 灵活召回策略:融合多种检索方式
- 上下文增强:重建语义关联和逻辑推理
| 功能模块 | 核心能力 |
|---|---|
| 多源知识接入 |
|
| 智能内容切片 |
|
| 高效语义向量化 |
|
| 自动索引构建 |
|
| 灵活召回 |
|
| 上下文增强 |
|
| 标签过滤 |
|
| QA干预 |
|
| 图片召回 |
|
| 重排序机制 |
|
快速上手
知识库提供“一次上传,多次调用”的知识管理模式:
- 创建知识库:定义知识库的基本信息、描述、分类和上下文增强策略。
- 上传文档:上传本地文件、飞书文档或网页链接,系统自动解析并分片。
- 数据处理:系统会完成文档切片、上下文增强、向量化等操作。
- 知识检索:根据用户问题检索相关切片,在智能体中使用知识问答时将基于检索结果生成回答。
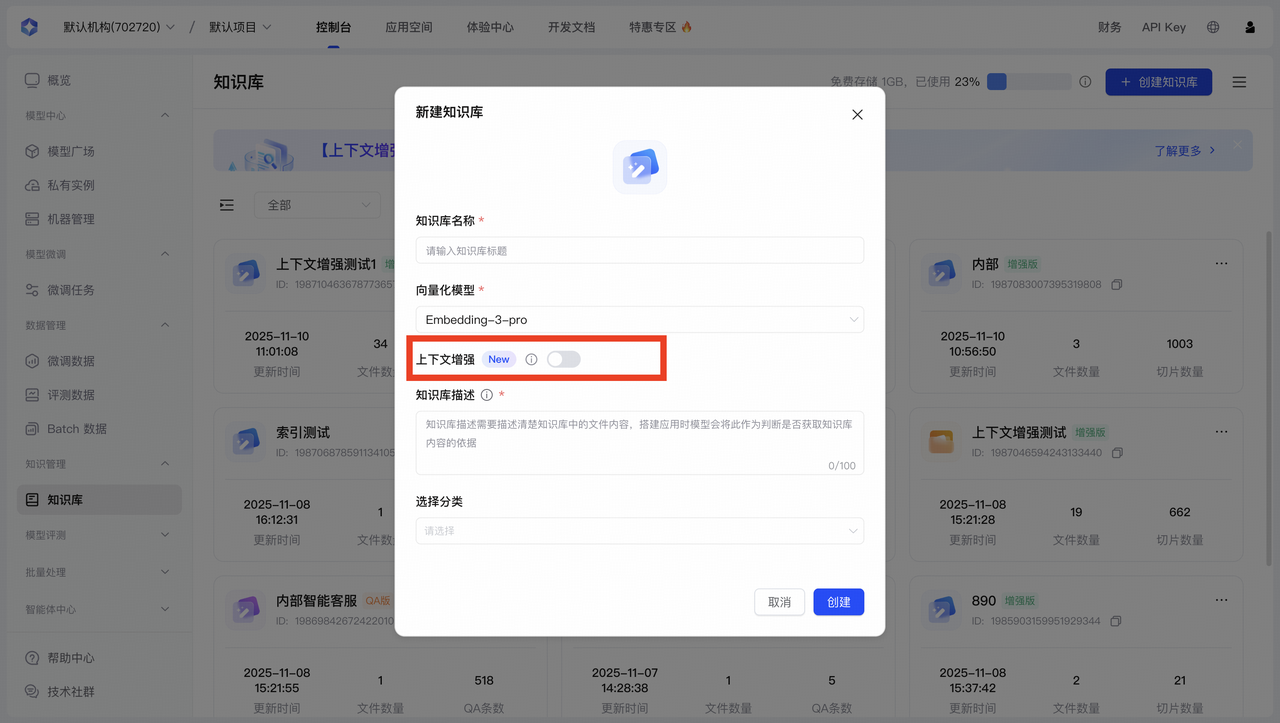
Step 1:创建知识库
进入知识库页面,点击右上角【创建知识库】。
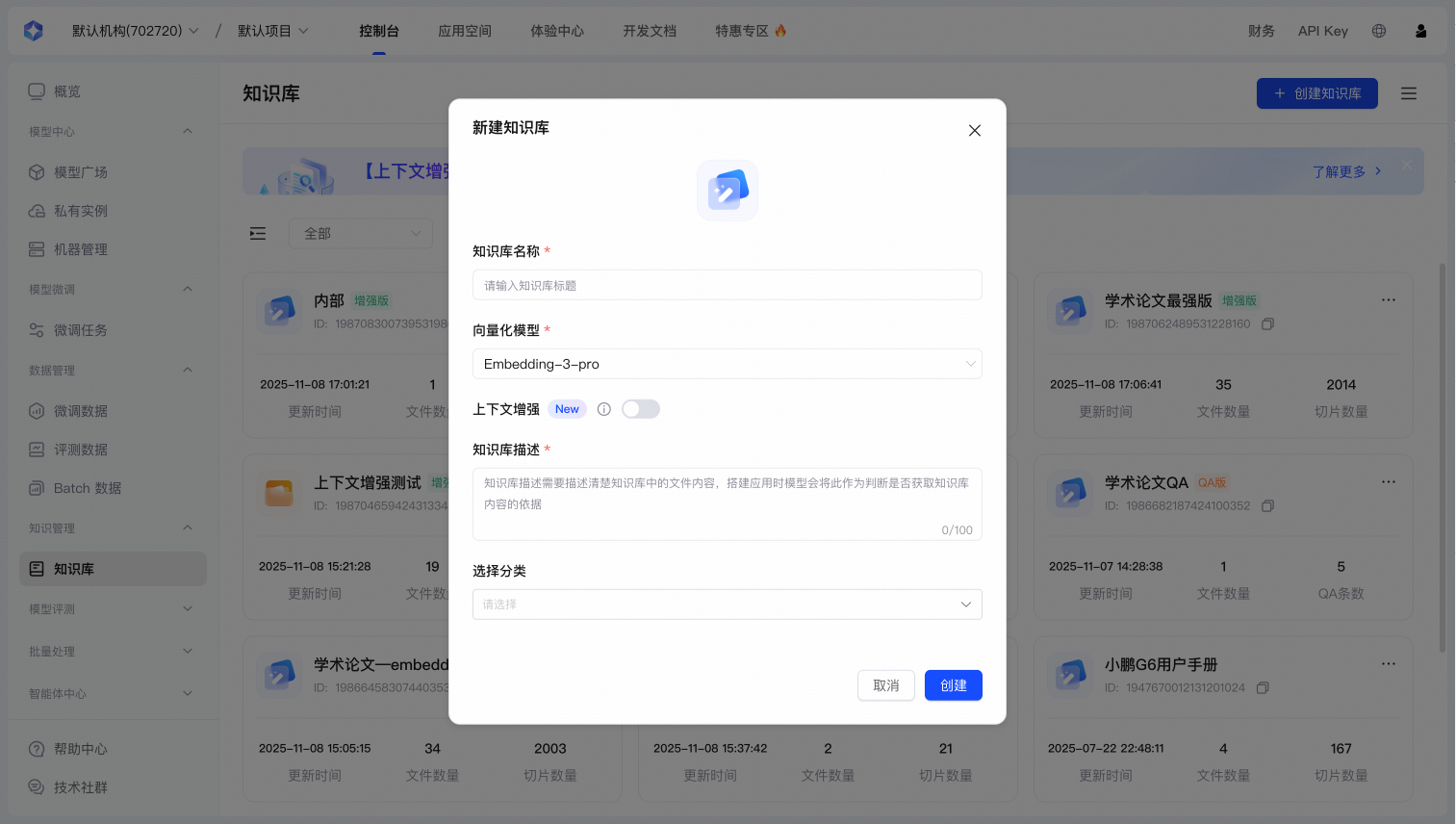
知识库版本(系统自动识别)
| 增强版 | QA版 | 普通版 |
|---|---|---|
|
|
|
| 配置项 | 说明 |
|---|---|
| 图标 | 为知识库选择独特图标,便于快速识别和管理 |
| 知识库名称 | 清晰、唯一的命名,支持中英文、数字及常用符号 |
| 向量化模型 |
|
| 分类 | 将知识库归入指定分类,方便结构化管理 |
| 描述 | 填写知识范围、用途等信息,建议详细填写以便模型调用 |
| 上下文增强 | 启用后保留文档中的关键语义与指代信息,提升复杂问答效果。 重要说明:
|
重要说明:启用上下文增强后会增加数据处理的Tokens消耗和时间,此操作不可逆,启用后无法回退至普通版。
Step2:上传知识
- 点击【上传知识】按钮开始上传流程
- 根据知识源类型选择相应的上传方式
- 完成上传后,可在文件夹中进行预览、分类和筛选操作
- 注意监控存储空间使用情况,避免超额费用
- 通过合理组织和上传知识,您可以构建结构清晰、检索高效的知识库系统。
支持的知识源
| 知识源 | 核心能力 | 关键注意事项 | 最佳实践 |
|---|---|---|---|
| 本地文档 |
| 单个文件大小建议不超过100MB |
|
| 飞书文档 | 动态关联飞书云文档,实现内容自动同步与更新 | 需要按照指引完成授权关联,确保系统有读取权限。详见知识库接入飞书文档https://zhipu-ai.feishu.cn/wiki/ULBawOiydiuD4fktiSVcgCzonwm |
|
| 网页链接 | 支持批量导入URL,自动抓取并消化网页的静态文本内容 |
|
|
| 问答对 (Q&A) |
|
| 两种核心用法:
|
存储与计费
- 默认空间上限:1 GB
- 超出容量计费:0.04元/GB/小时
- 操作建议:监控存储空间使用情况,避免超额费用
Step 3:知识处理
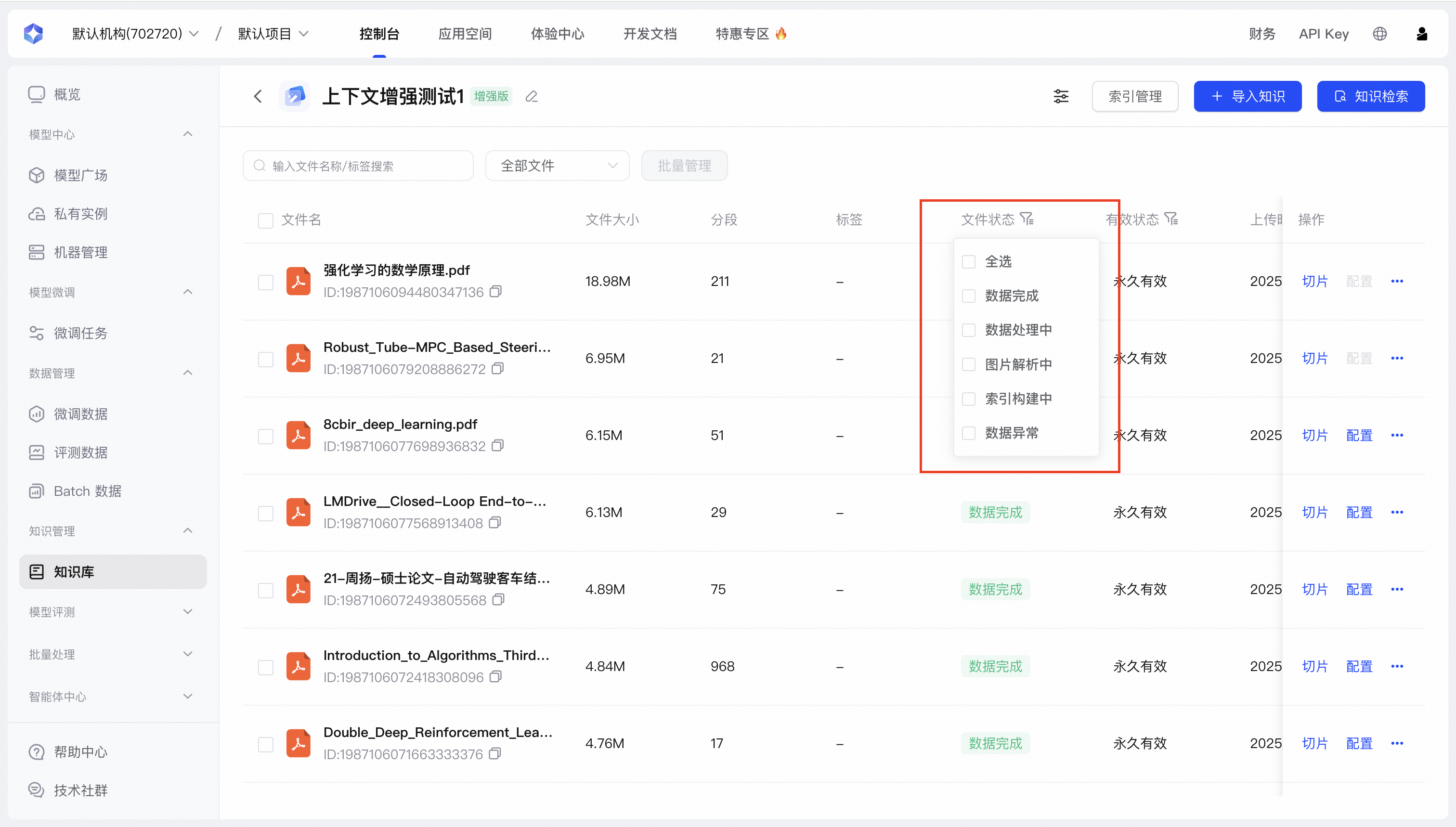
处理流程
| 处理阶段 | 用户选项 | 说明 |
|---|---|---|
| 文档解析与图片解析 | 自动处理 |
|
| 切片策略应用 | 基础/高级模式 |
|
| 上下文增强处理 | 自动处理(增强版) |
|
| 切片向量化 | 自动处理 |
|
| 处理状态指示 | 实时反馈 |
|
处理状态
| 处理阶段 | 核心价值与系统行为 | 用户配置 |
|---|---|---|
| 文档智能解析 | 核心价值:精准识别文档的内在结构(如标题、段落、表格、列表),并提取核心图文信息,最大程度地还原文档的原貌。 系统行为:自动化解析,保留关键格式与元素。 此过程全自动进行,无需用户干预。 如需系统深入解析图片中的内容(如图表、流程图),请在文档的高级设置中开启图片解析功能。 | 无需配置(自动处理) |
| 语义单元切片 | 核心价值:将长文档智能拆解为一个个语义完整、大小适中的知识片段。这是确保高精度召回和生成高质量、逻辑连贯答案的关键一步。 系统行为:根据选定策略进行内容分割。 提供两种灵活的模式:
| 选择切片模式(基础/高级) |
| 上下文关联增强 | 核心价值:为独立的知识片段重建其原始上下文,建立段落间的逻辑关联。这是系统能够进行深度推理、回答需要结合前后文的复杂问题的核心能力。 系统行为:构建知识片段的上下文内容。 此功能在您创建”增强版”知识库时自动启用。启用后,系统才能真正理解并回答跨段落的复杂提问。 | 创建时选择是否启用上下文增强 |
| 语义向量化 | 核心价值:将所有文本片段转化为高维度的数学向量,使其能被计算机理解和比较。这是实现”用自然语言提问,找到最相关内容”的技术基石。 系统行为:调用向量化模型进行计算。 此过程基于您选择的向量化模型全自动完成,无需任何操作。 | 选择向量化模型(创建时配置) |
| 处理状态反馈 | 核心价值:提供清晰、实时的处理进度反馈,让您对数据处理的每个环节了如指掌,并能预估完成时间,提升操作的确定性。 系统行为:监控处理队列和任务状态。
| 无需配置(自动反馈) |
Step4:知识检索测试
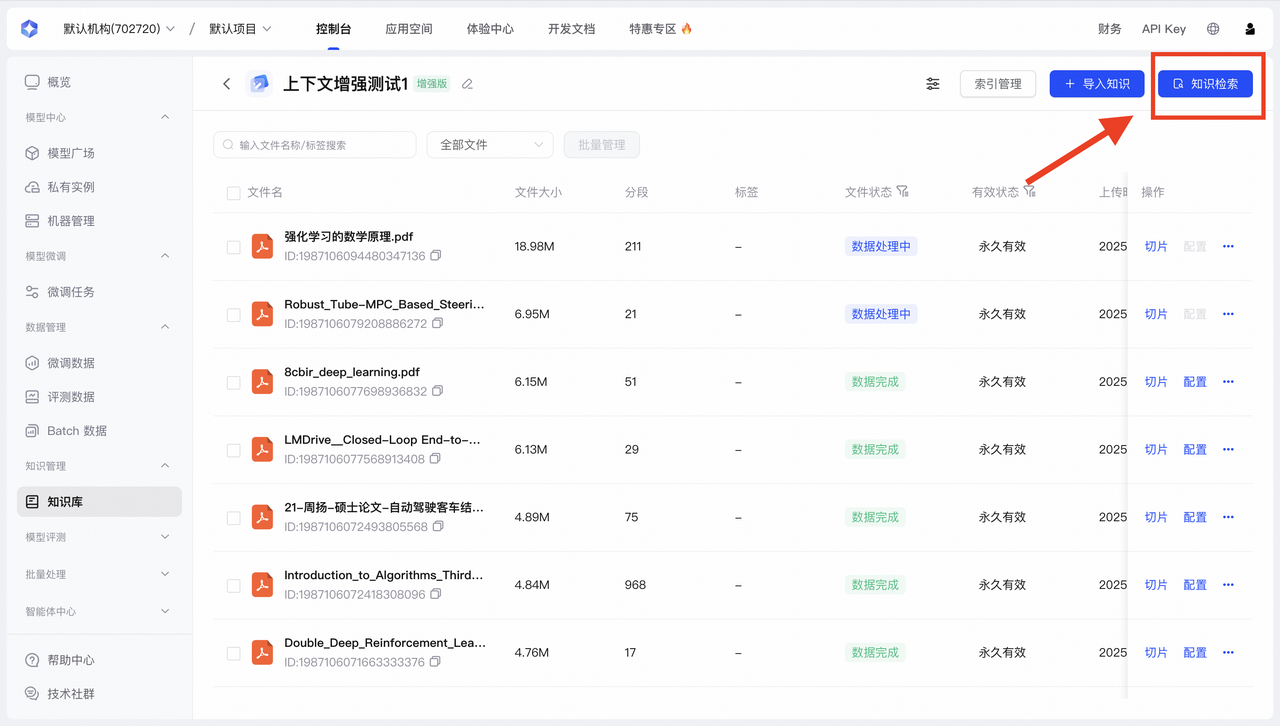

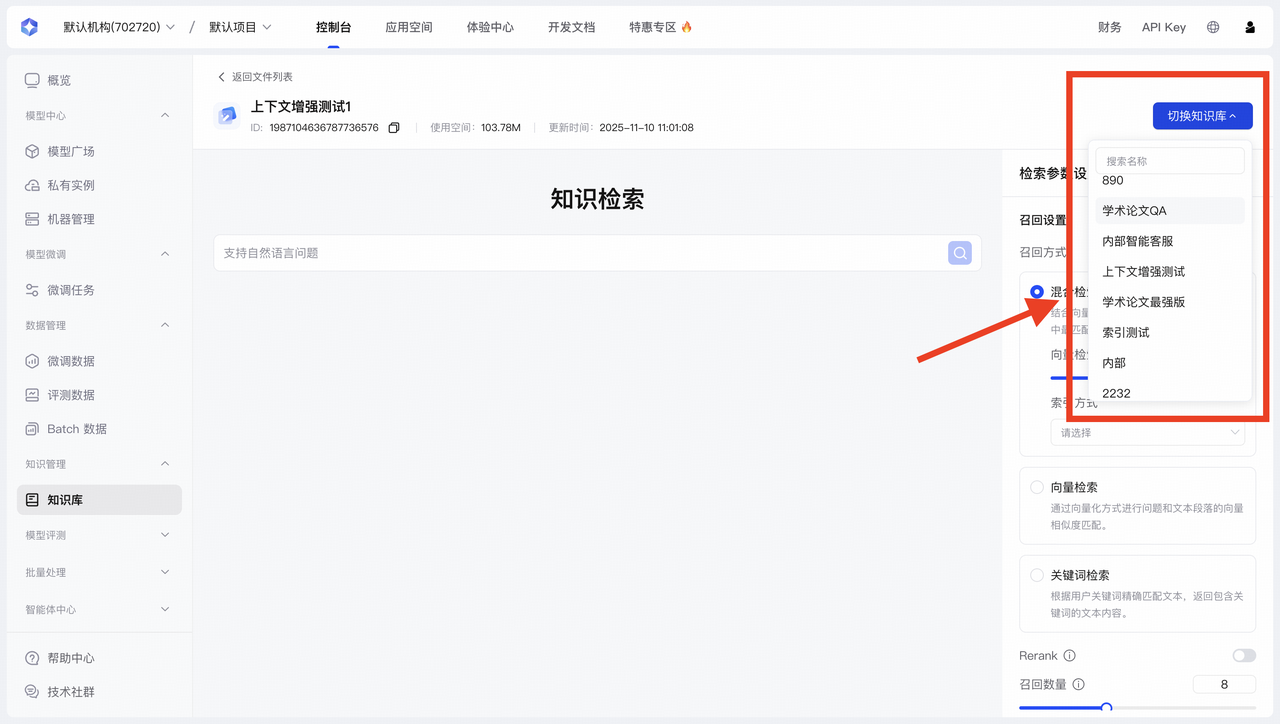
| 功能模块 | 核心能力 | 最佳实践 |
|---|---|---|
| 知识检索 |
|
|
| 参数调优 |
|
|
| 结果分析 |
|
|
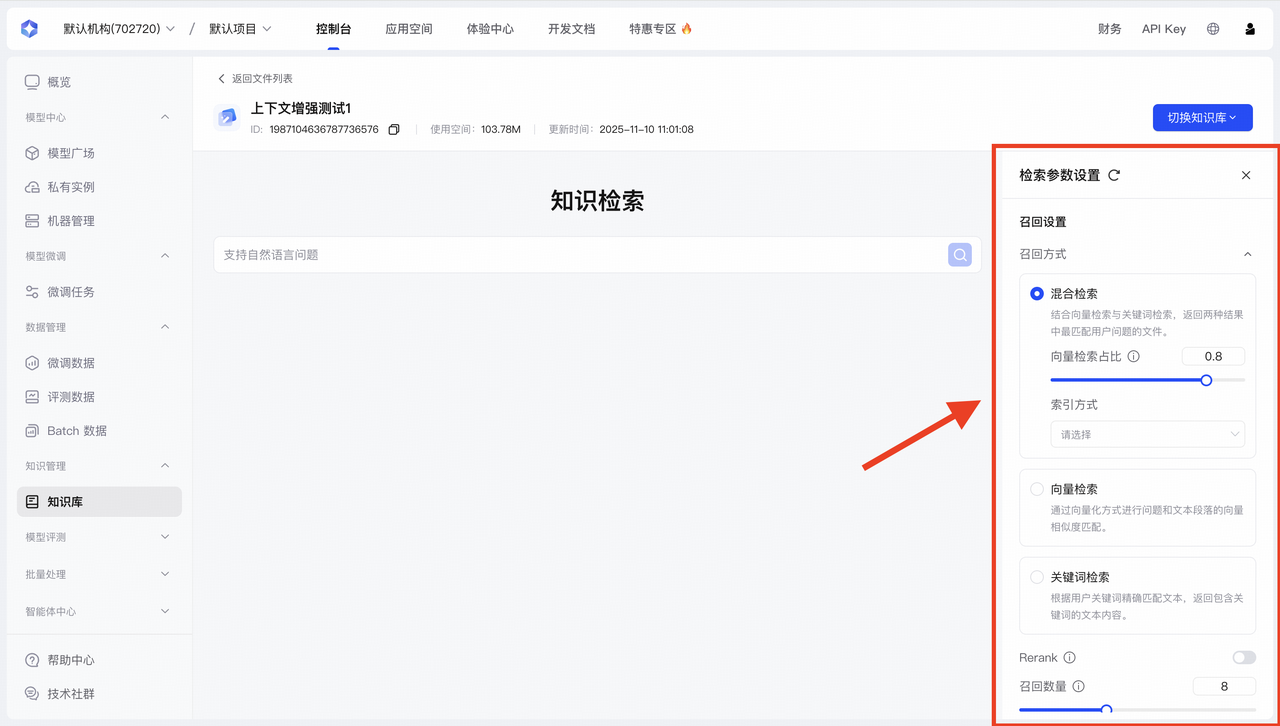
参数调优指南
| 参数类型 | 子参数 | 具体描述 | 调优建议 |
|---|---|---|---|
| 召回方式(这决定了系统如何在知识库中查找信息) | 1. 混合检索(推荐使用) |
| 向量检索占比建议初始值0.8,可根据需求调整 |
| 2. 向量检索 |
| 适用于问题表述与文档不一致的场景 | |
| 3. 关键词检索 |
| 适用于查找特定术语、产品名称或代码 | |
| 召回分数 | 最低相关度分数 |
| 建议使用默认设置:0.3 |
| 召回数量 | 最大返回结果数 |
| 简单问题设置较小值,复杂问题设置较大值 |
| 重排模型(结果重排序) | 二次排序 |
| 重要查询建议开启 |
| QA干预 | QA优先匹配 |
| 适用于有标准化回答的常见问题 |
| 文件范围控制 | 按标签筛选 |
| 适用于需要在特定领域内查找的场景 |
三、主要功能介绍
1. 上下文增强
🏅 上下文增强是一项先进的RAG流水线预处理技术,通过为孤立的知识切片添加强上下文信 息,使切片恢复其在原文中的语义关联,从根本上提升检索质量和问答准确性。
| 技术维度 | 实现方式 | 优势效果 |
|---|---|---|
| 工作原理 |
|
|
| 技术架构 |
|
|
- 进入【创建知识库】/【知识库编辑】界面。
- 在创建或编辑知识库时,找到并启用【上下文增强】开关。
- 保存设置。此后所有新上传的内容都将自动应用增强处理。
- 这是一个单向操作:知识库一旦升级为“增强版”,将无法回退到标准版。这是因为我们重构了其底层的数据结构。
- 会产生额外成本:该功能需要消耗更多的计算资源进行深度处理,因此会产生额外的计算费用。其价值在于大幅提升检索质量,尤其适合对准确性和完整性有高要求的场景。
- 存量数据需要重新处理:对已有的知识库开启此功能,系统需要对库内所有文档进行一次性的重新处理,根据数据量大小,可能需要一些时间。
2. 切片策略
| 切片方式 | 支持格式 | 示例结构 | 技术特点 | 最佳应用场景 |
|---|---|---|---|---|
| 按段落标题 | PDF、DOCX、TXT、MD | 一、概述 1.1 背景介绍 |
|
|
| 按页切片 | PDF、PPTX | 每页为一个知识单元 |
|
|
| 按问答对 | DOCX、TXT、MD | 问题+答案结构 |
|
|
| 按行切片 | CSV、XLSX | 每行记录一条知识 |
|
|
| 自定义切片 | 所有文本类 | 自定义分隔符,如 === |
|
|
3. 切片管理
| 功能项目 | 具体描述 | 备注 |
|---|---|---|
| 查看切片 | 支持查看单个知识片段的完整内容,包括系统为其生成的上下文增强信息,让您清晰了解AI在回答问题时到底”看”到了什么。 |  |
| 原文定位 | 在原文预览中,系统会自动高亮并滚动到该片段的原始位置,方便您快速溯源和核对。 |  |
| 编辑切片 | 直接编辑知识片段的文本内容或其上下文描述,以纠正系统解析的错误或更新过时的信息。 |  |
| 上传图片 | 支持在知识片段中上传图片(如图表、示意图)。上传后,系统将自动处理该图片,使其能被未来的检索查询到。 | 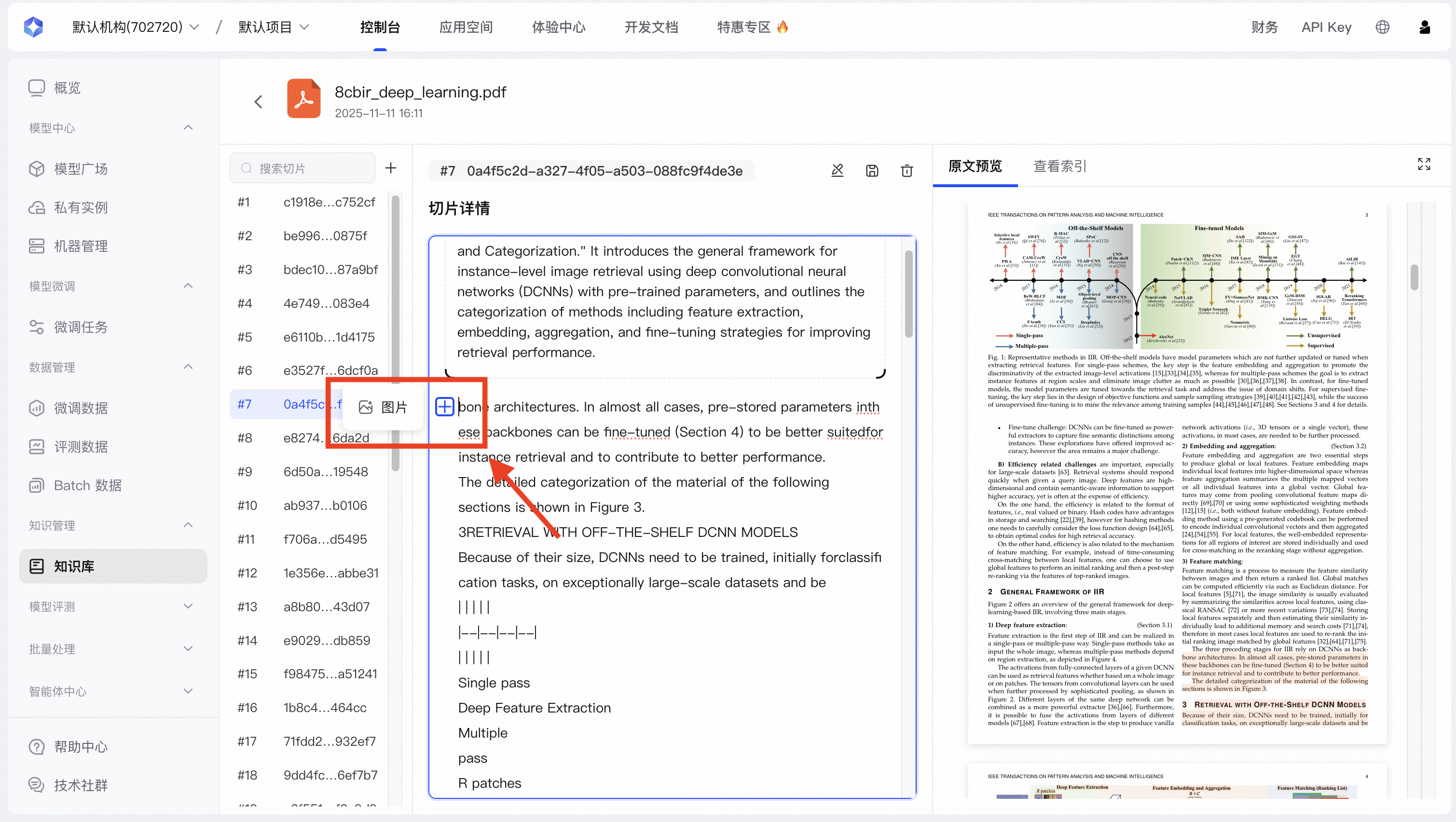 |
| 新增切片 | 允许您在文档中手动创建一个全新的知识片段,以补充系统未能自动抓取到的”隐性知识”或关键信息。支持直接从原文中复制内容。 | 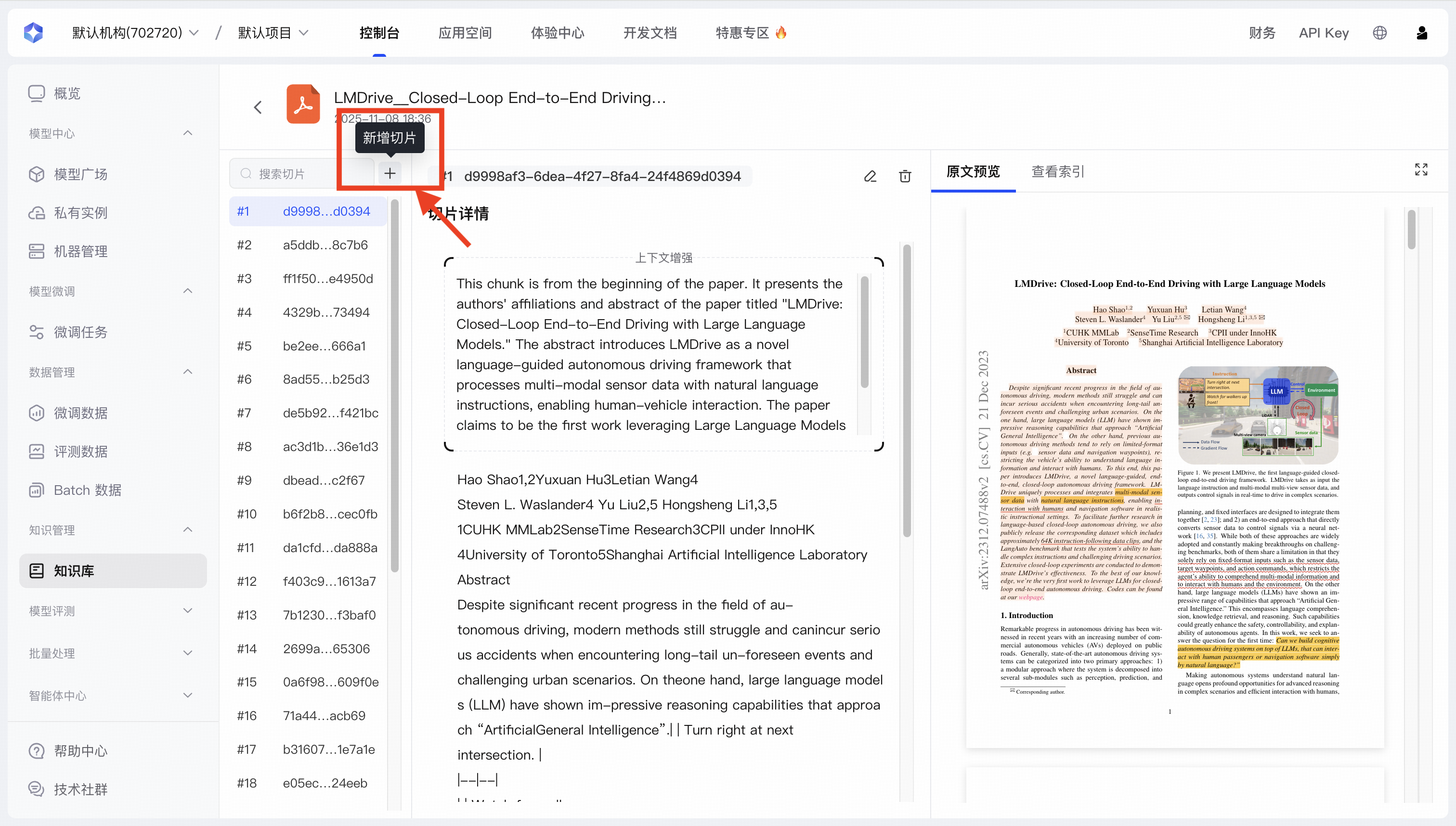 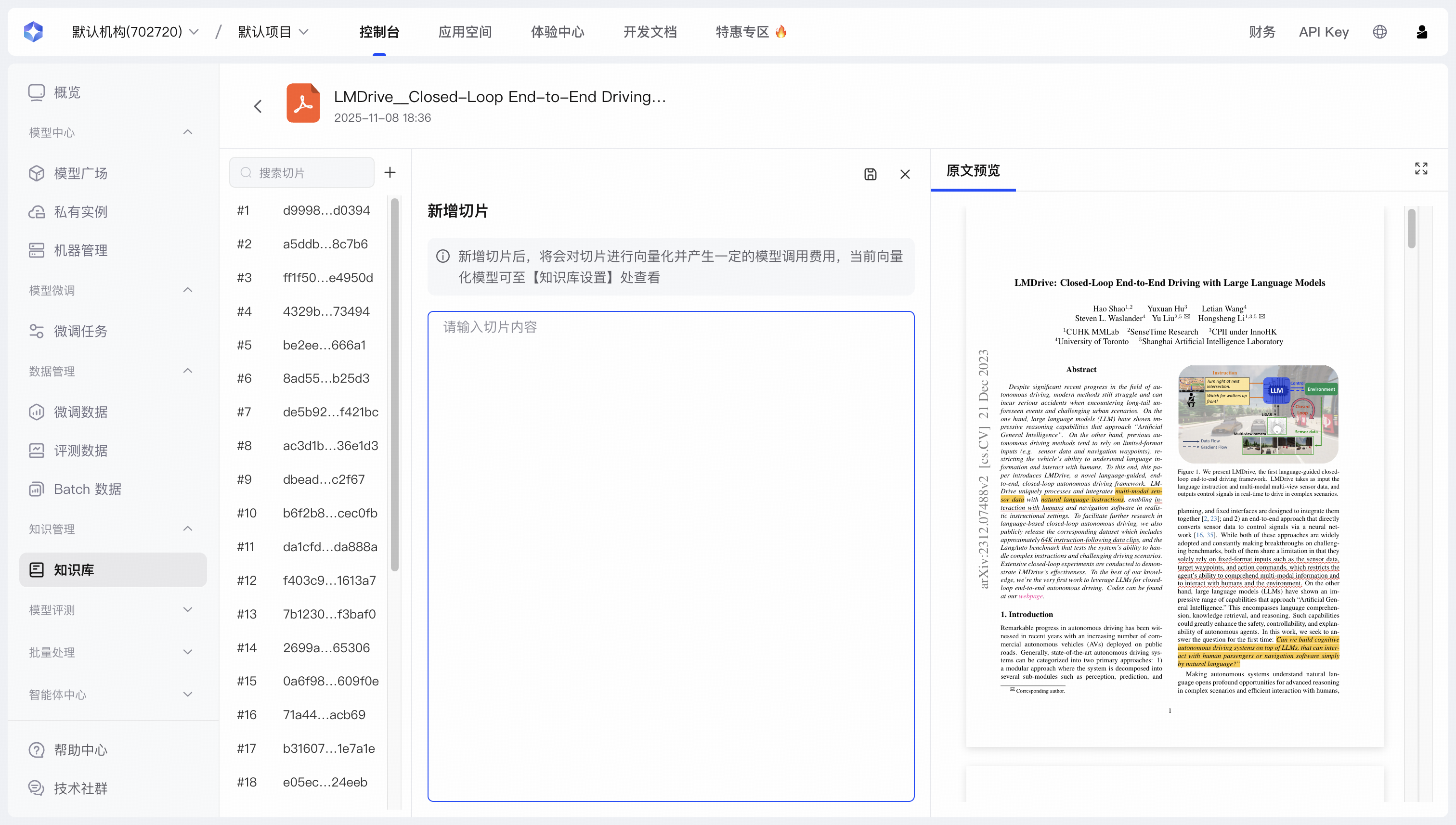 |
4. 图片解析
此功能为白名单功能,可联系商务/客服开通。
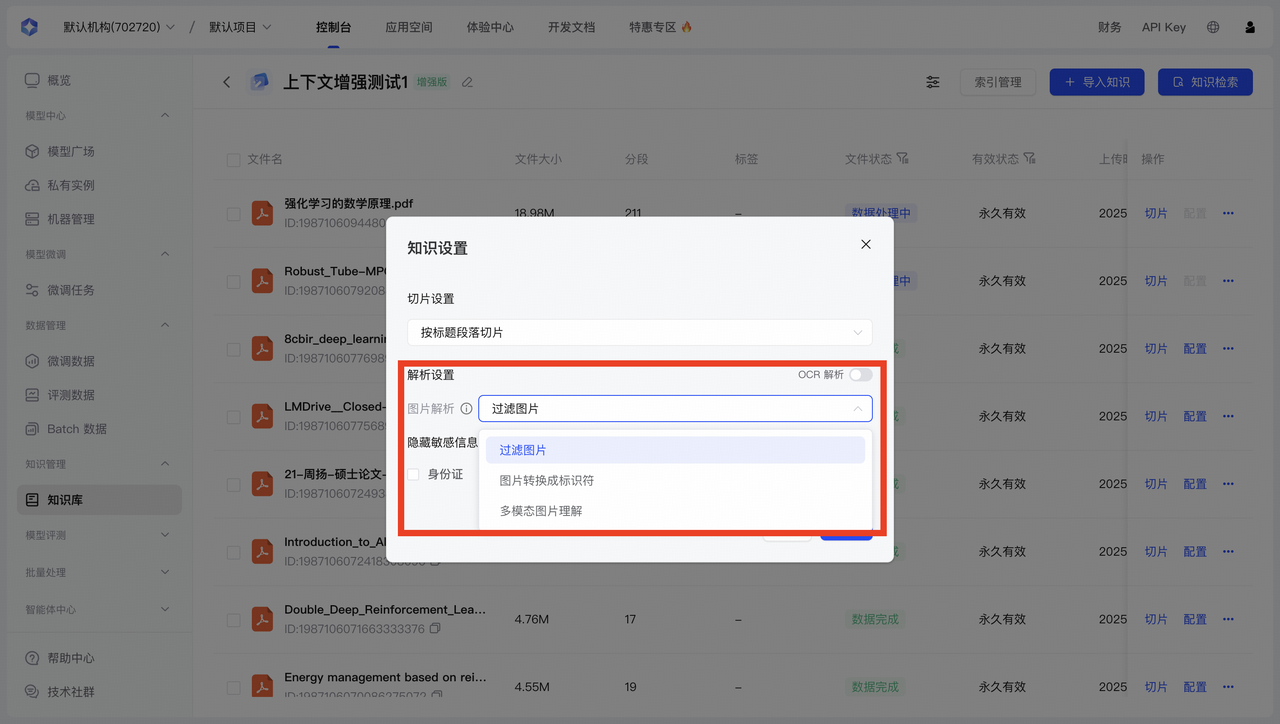 当前支持对 PDF、DOCX、XLSX文件中的图片进行解析,功能包括:
当前支持对 PDF、DOCX、XLSX文件中的图片进行解析,功能包括:
| 处理模式 | 技术机制 | 应用场景 | 资源消耗 | 效果预期 |
|---|---|---|---|---|
| 过滤图片 |
|
| ⭐最低 |
|
| 图片占位符 |
|
| ⭐⭐低 |
|
| 多模态图片理解 |
|
| ⭐⭐⭐较高 |
|
实施建议:对于含有大量图表、流程图或技术图示的专业文档,建议使用多模态图片理解模式,尽管处 理资源消耗较高,但能显著提升回答质量。对于图片数量多但内容价值低的文档,可采用图片占位符模 式平衡资源和效果。在测试阶段,建议先尝试不同处理模式并评估对最终问答质量的影响,再确定最佳 配置。
5. 文档标签

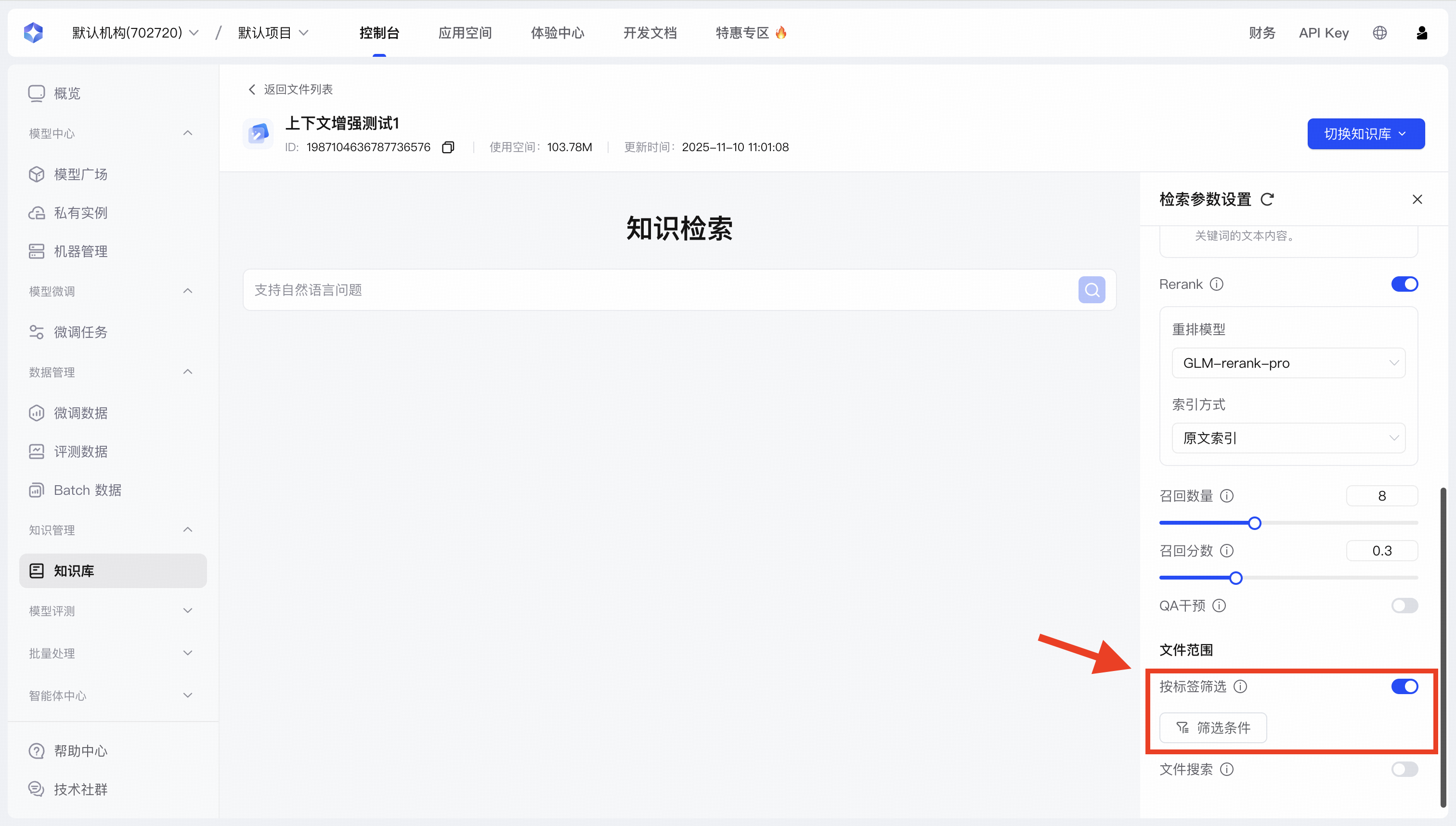
| 功能维度 | 技术参数 | 实现价值 |
|---|---|---|
| 标签上限 | 每知识库最多50个标签 | 提供足够的分类维度,同时防止过度复杂化 |
| 标签类型 |
| 满足不同数据分类需求,提供结构化检索基础 |
| 生成方式 |
| 平衡精确度与便捷性,适应不同建库场景 |
| 系统集成 | 与知识检索引擎深度融合 | 实现语义+标签混合过滤,提升检索精准度 |
实施建议:在初始构建知识库时,建议先设计标准化的标签体系,确保命名一致且具有业务意义。对 于大型知识库,可先使用AI自动生成标签作为基础,再由专业人员审核优化。定期检查和更新标签体 系,以适应业务变化需求。标签名应简洁明确,避免使用太过通用或模糊的术语,确保其在检索时能 提供有意义的过滤价值。
6. QA干预

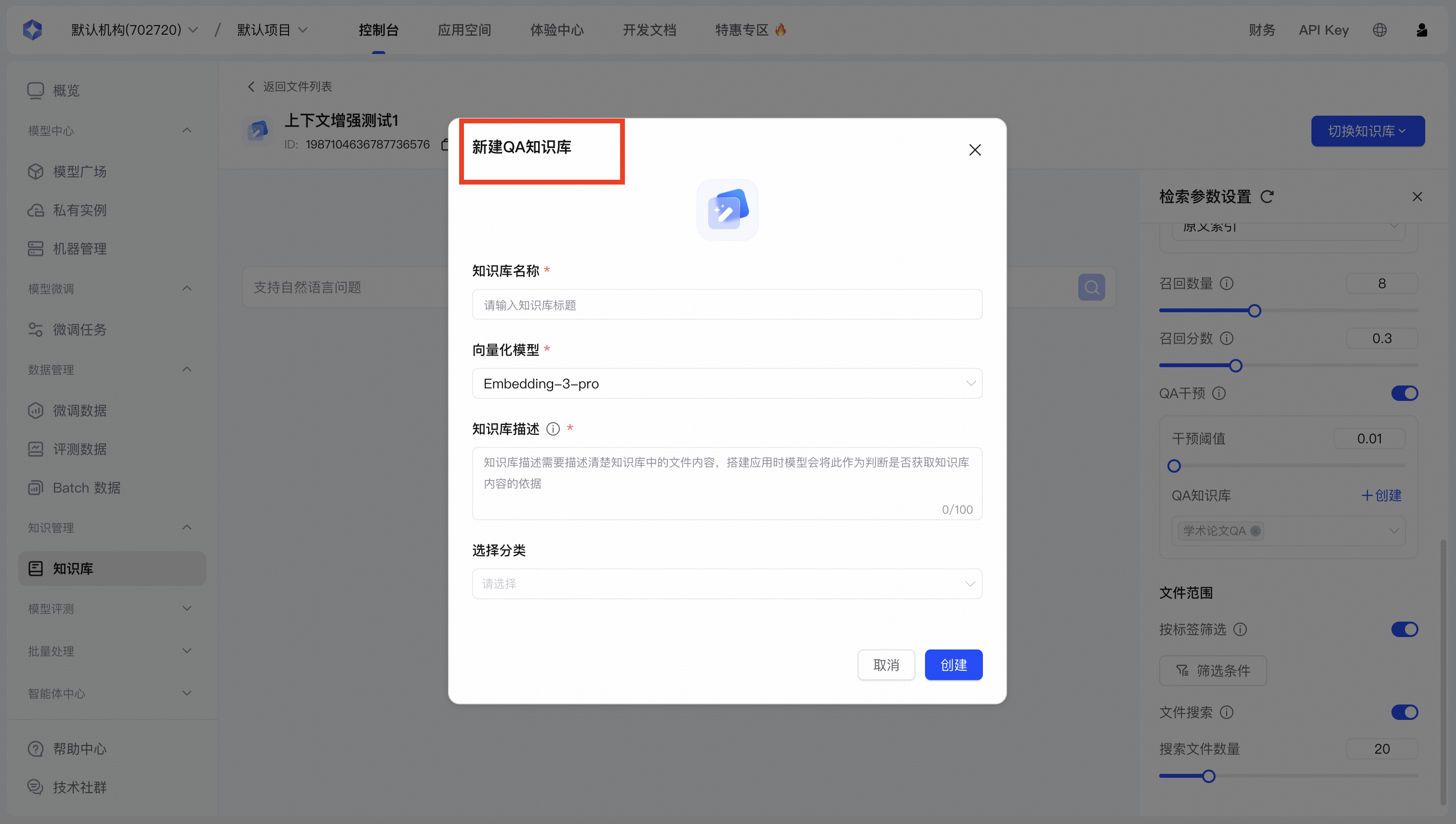
| 功能维度 | 具体说明 |
|---|---|
| QA知识库定位 | 专为精准问答设计的特殊知识库 |
| 内容组织方式 | 结构化问答对(Q&A pairs),每个问题对应一个明确的标准答案 |
| 召回优先级 |
|
| 与重排功能的关系 |
|
| 与非QA知识库协作 | 双层召回机制,形成优先QA匹配、备选标准召回的完整解决方案 |
| 适用场景 |
|
| 设置步骤 |
|
实施建议:在构建QA知识库时,建议从用户实际提问数据出发,优先添加高频问题和关键业务问题。 保持问题表述自然,与用户实际提问方式一致,避免过于技术化或形式化的表述。定期审查QA匹配 数据,将频繁触发但匹配度不高的问题进行优化。对于复杂领域,考虑构建多个专题QA知识库,并 根据问题特点选择性关联,提高答案精准度和系统效率。
四、知识库管理
| 操作类型 | 说明 |
|---|---|
| 查看知识库 | 查看详细信息与文档结构 |
| 编辑知识库 | 修改名称、描述、图标、模型或上下文增强设置 |
| 复制知识库 | 复制当前知识库 |
| 删除知识库 | 永久删除,无法恢复 |
| 知识库内文件操作 | 预览、重命名、更新(URL类可重新抓取)、删除、下载等 |
| 切片操作 | 查看、编辑、删除或手动新增知识切片 |
五、常见问题
| 错误类型 | 可能原因 | 解决方案 | 预防措施 |
|---|---|---|---|
| 上传失败 |
|
|
|
| 切片异常 |
|
|
|
| 向量化失败 |
|
|
|
| 检索为空 |
|
|
|
✨让知识更智能,让回答更可信。
立即创建你的知识库,开启高质量智能问答体验。