场景介绍
大模型凭借其卓越的数据处理能力以及广泛的应用潜力,正在逐步转变为教育行业创新的强大引擎。未来,随着大模型的融入,个性化教育将迎来新生,改变现有千人一面的局面。在作文批改存在较多问题,如教师工作量大、批改标准难以统一、个性化反馈不足。一份作文的深度批改至少需要15-20 分钟,这意味着语文教师批改一次作文就要花费8-10 小时。更重要的是,不同教师的批改标准存在差异,同一篇作文可能得到不同的评价结果。 学生的作文评价标准和重点也都不尽相同,如有记叙文、说明文、应用文等多种文体。记叙文注重情节完整性和语言生动性,说明文强调逻辑清晰和表达准确,应用文则要求格式规范和内容实用。 大模型能力的提升为解决这一问题提供了新思路。某知名教育平台通过引入GLM模型,实现了作文批改的智能化升级,不仅大幅提升了批改效率,更在评价准确性和个性化反馈方面取得了显著进步。业务需求
解决方案
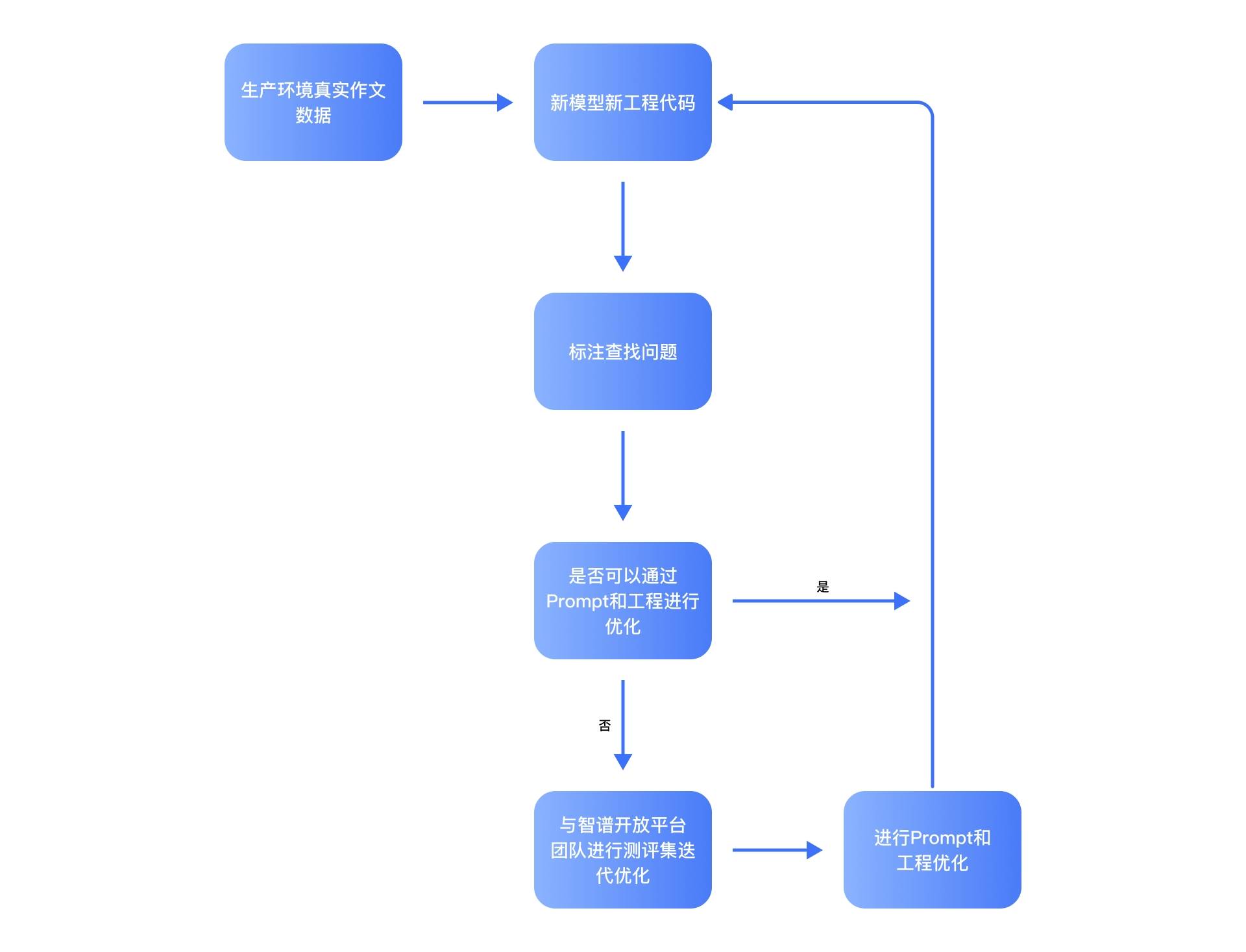
一、方案框架
方案架构
传统 VS 大模型效果提升
某教育平台的客户经过与智谱开放平台的深度合作,在产品效果上实现了飞跃性的提升。特别是在作文评测领域,大模型的强大功能使得评测效果大幅提高,教学体验也得到了显著优化。 大模型的运用,使得对学生的学习行为和需求的解析更为迅速和精准,进而提供了更为定制化的作文评测服务。同时,大模型在自然语言处理和图像识别等领域的卓越能力,为作文评测带来了全方位的显著进步。在错别字、词标点符号等提取效果来看均有不同程度的提升,显著优化了教学体验和评测效果。 通过与智谱开放平台的合作,客户不仅在教学质量和效果上实现了显著进步,更为学生打造了更加多元和个性化的学习旅程。模型选型
GLM-4.7 是智谱推出的高智能语言模型。作为智谱的最新旗舰产品,GLM-4.7 在语言理解、逻辑推理、指令遵循以及长文本生成等多个领域均取得了显著的进展。在最近一次的SuperBench大型模型评测中,GLM-4.7 荣膺世界前三的排名,成功打破了之前由国外模型独占鳌头的局面。 GLM-4.7 擅长高精细度的复杂场景。在学生作文的广阔天地中,不同年级、不同体裁的习作要求不同,语言风格呈现出多样化,所以对于基座模型就有极高的要求。记叙文语言优美,说明文科学严谨,有的洋溢着文学色彩,有的则充满辩证思维。GLM-4.7 语言模型如同一位经验丰富的同行AI助教,能够准确识别并深入理解这些不同的语言表达,给到清晰、深度的个性化评价。通过GLM-4.7模型,我们致力于提升作文评价的质量,让每位学生的创作才华在文字中得到充分的认可和展现。二、方案详情
在评价作文的过程中,需要考虑多个因素,包括:错别字、词、标点识别;好词好句识别、内容评价、逻辑结构评价、语言表达评价、段落评价等。我们可以利用大模型高效、准确、丰富知识的优秀特点,对学生作文进行综合打分。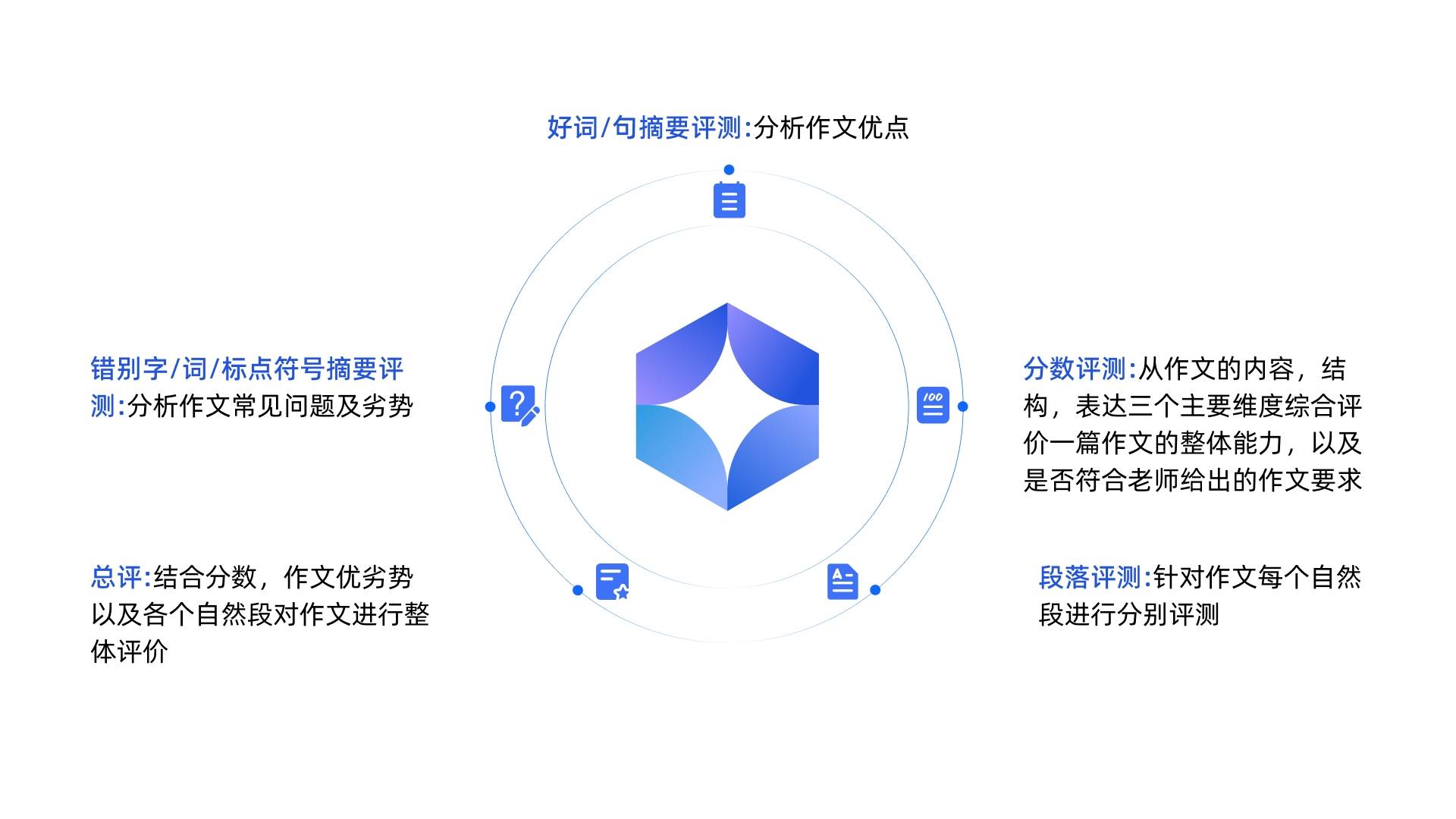
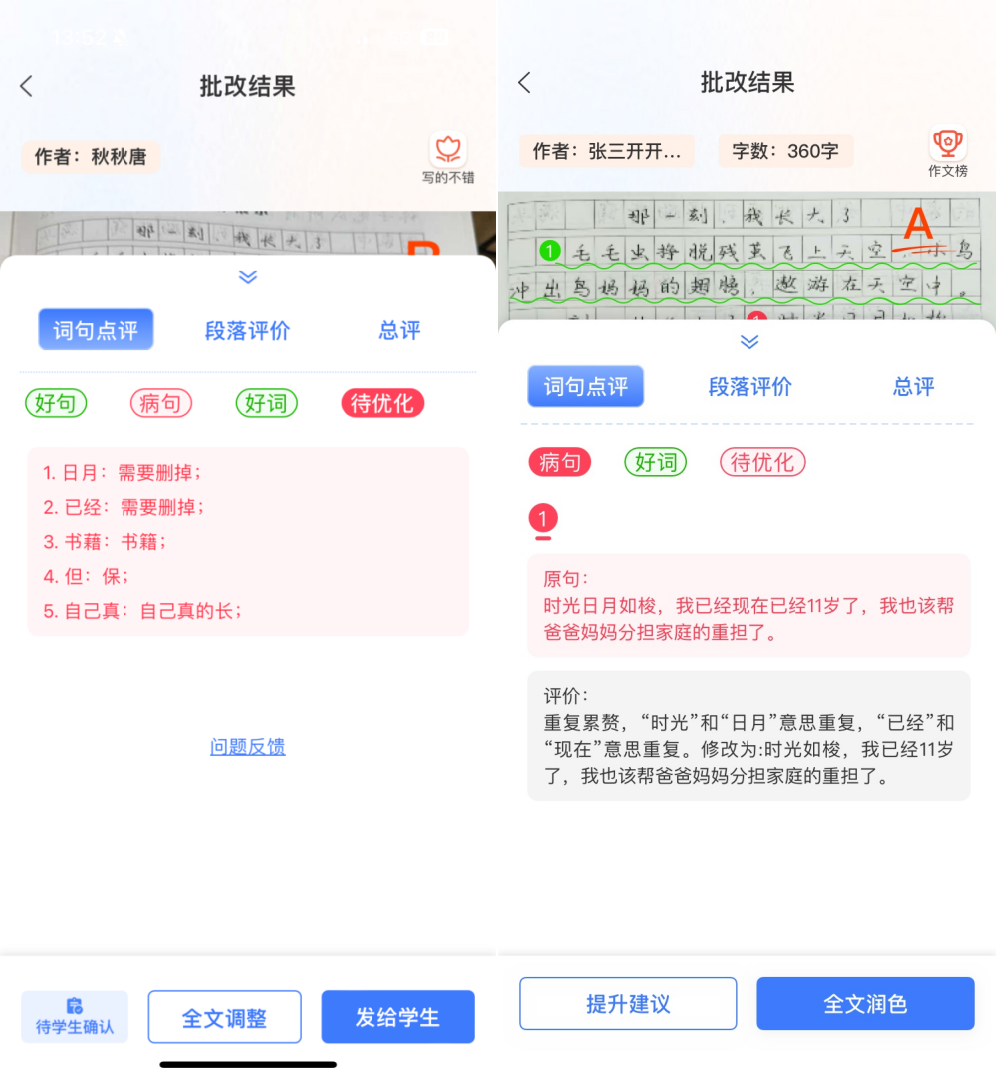
场景一:抓取错词错句
在作文批改过程中,识别错词错句及优化病句的建议,依赖于模型深厚的语言处理能力和对长文本的细致分析能力。该模型能够精确地定位每一个错误,并在理解上下文的基础上,提出符合学生年级和作文主题的修改建议。- 深层次语义理解:大型语言模型具备深入理解句子内涵的能力,即便处于复杂语境,也能有效辨识出不恰当的词汇和错误的句子构造。
- 大规模数据识别:这些模型在训练过程中接触了巨量的文本资源,这让它们能够辨别出哪些词汇或句子搭配在正式书面语中较为罕见,进而准确标出错词错句。
- 上下文相关性评估:模型有能力基于上下文来判定词语和句子的恰当性,即便是语法正确但语境不适宜的用词也能被有效识别。
- 语法规则习得:在训练过程中,模型吸收了众多的语法规则知识,这使其能够检测句子是否遵守了语法标准。
场景二:好词好句识别评测
在运用修辞技巧方面,学生作文中的隐喻、双关等深层次含义,对解读能力提出了更为严峻的挑战。GLM-4.7模型具备洞悉这些弦外之音的能力,能够挖掘作文背后的深层思想。- 文学素养模拟:经过训练,大型模型能够模仿一定水平的文学品质,辨别出那些具有表现力、形象生动或富含智慧的词汇和句子。
- 风格与修辞的辨识:该模型有能力辨别不同的写作风格和修辞技巧,进而挑选出那些能够提升文章感染力的佳词妙句。
- 情感与语气的解析:模型能够对句子的情感倾向和语气进行解析,识别出那些能有效表达作者意图和情感的优质语句。
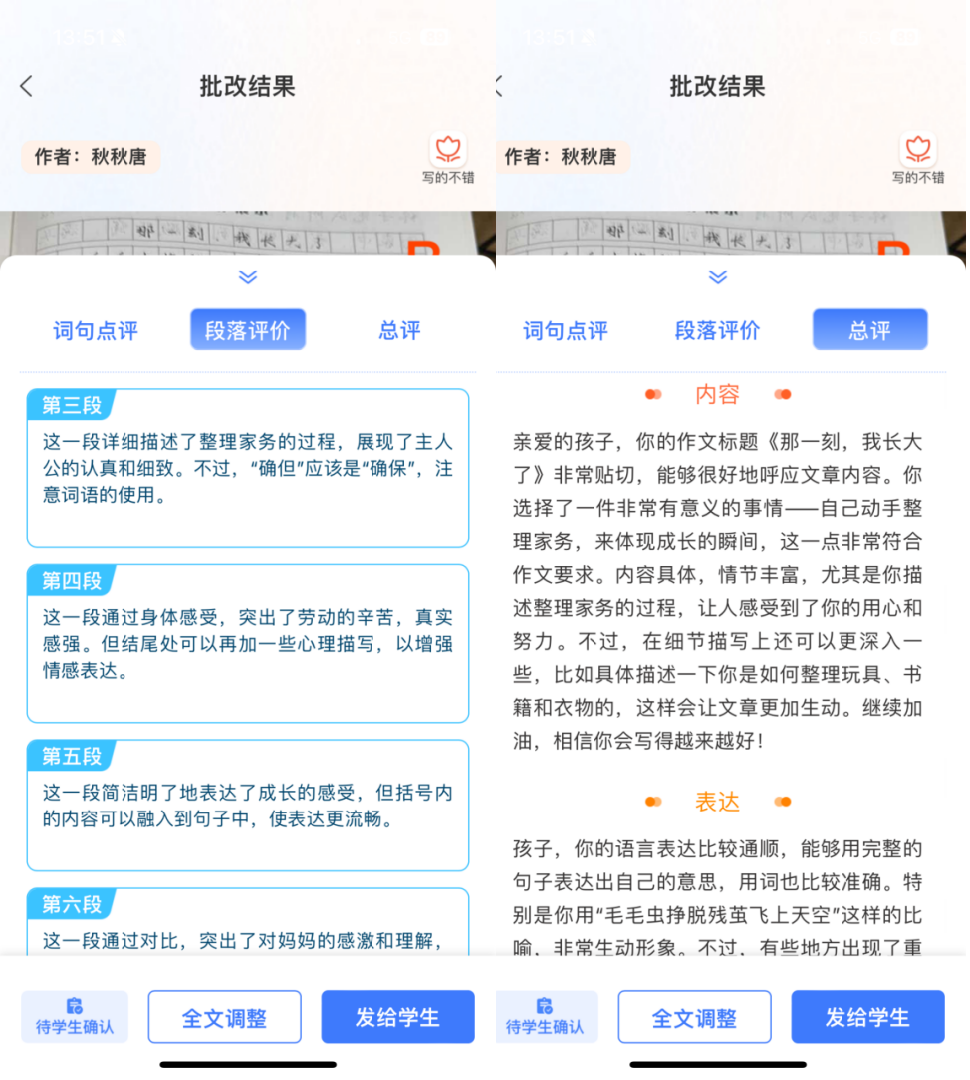
场景三:作文综合评价评分
作文的内容往往涉及特定的文化背景和历史知识,这对于评价者来说是一个挑战。GLM-4.7模型凭借其丰富的知识库,能够精准把握这些文化细节,确保评价的准确性。逻辑结构和论证分析是评价作文不可或缺的部分。GLM-4.7模型能够识别并评估论点的合理性,确保作文的逻辑性和论证的有效性得到恰当的评价。- 综合评价能力:大型模型可以综合考虑文章的内容、结构、语言等多个维度,给出全面而细致的评价。
- 标准化的评分系统:模型可以根据预定的评分标准,如内容完整性、逻辑性、语言准确性等,对作文进行客观评分。
- 个性化反馈:模型能够根据学生的写作特点和水平提供个性化的评价和建议,帮助学生有针对性地提高。
- 一致性保证:与人工评分相比,模型评分可以保证评价标准的一致性,减少主观差异带来的评分不公。
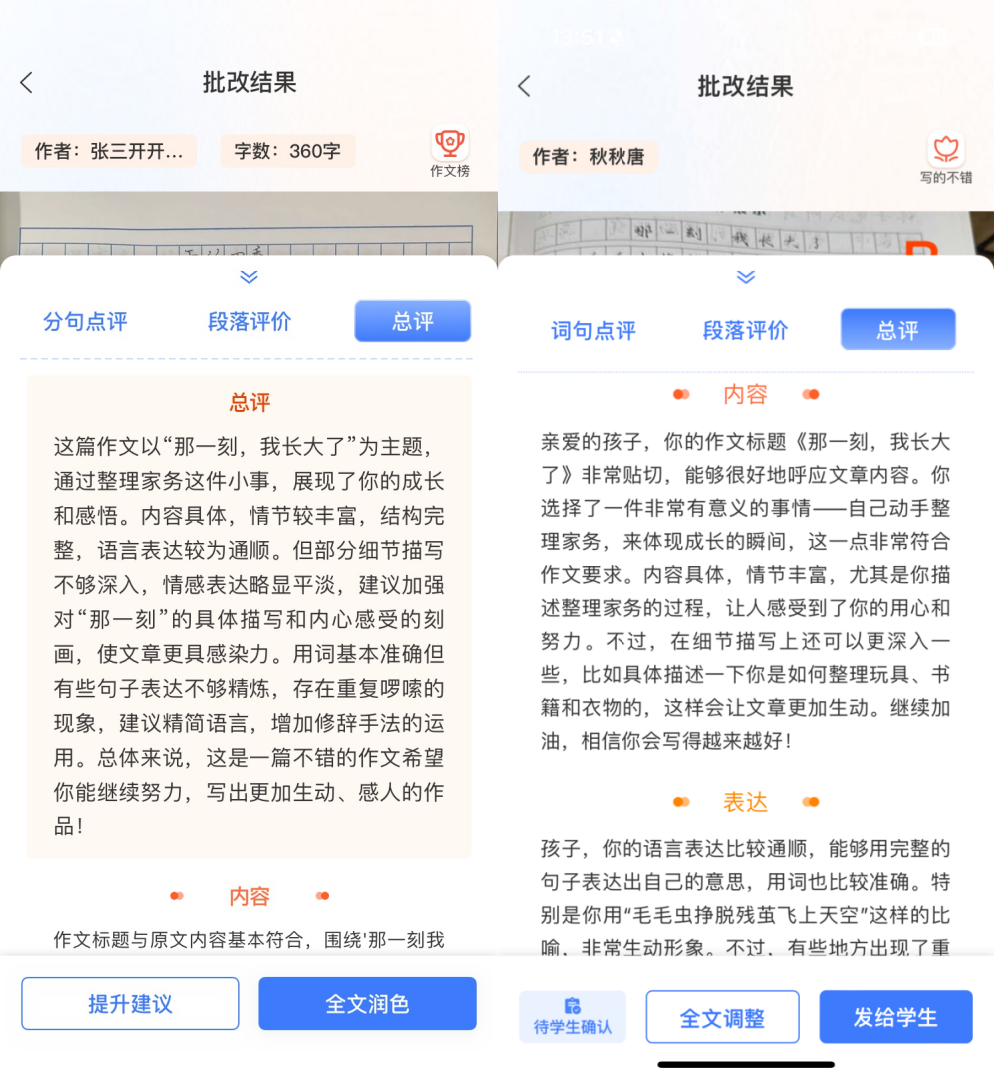
三、模型输入数据示例及效果
错别字抓取&修改:
好词好句点评: