

文本模型
GLM-4.5
新旗舰基座 GLM-4.5 系列模型上线,上新期间狂欢特惠,更有推荐好友送大额 Tokens 活动!立即了解
概览
GLM-4.5 和 GLM-4.5-Air 是我们最新的旗舰模型系列,专为智能体应用打造的基础模型。GLM-4.5 和 GLM-4.5-Air 均使用了混合专家(Mixture-of-Experts)架构。GLM-4.5 总参数达 3550 亿,激活参数为 320 亿; GLM-4.5-Air 采用更精简的设计,总参数为 1060 亿,激活参数为 120 亿。 GLM-4.5 和 GLM-4.5-Air 使用了相似的训练流程:首先在15万亿令牌的通用数据上进行了预训练。然后在代码、推理、智能体等领域的数据上进行了针对性训练,并将上下文长度扩展到 128k,最后通过强化学习进一步增强了模型的推理、代码与智能体能力。 GLM-4.5 和 GLM-4.5-Air 在工具调用、网页浏览、软件工程、前端编程领域进行了优化,可以接入 Claude Code、Roo Code 等代码智能体中使用,也可以通过工具调用接口支持任意的智能体应用。 GLM-4.5 和 GLM-4.5-Air 均采用混合推理模式,提供两种模式:用于复杂推理和工具使用的思考模式,以及用于即时响应的非思考模式。可通过 thinking.type 参数启用或关闭(支持 enabled 和 disabled 两种设置),默认开启动态思考功能。输入模态
文本
输出模态
文本
上下文窗口
128K
最大输出Tokens
96K
GLM-4.5 系列模型
GLM
GLM-4.5
我们最强大的推理模型,3550亿参数
AIR
GLM-4.5-Air
高性价比 轻量级 强性能
X
GLM-4.5-X
高性能 强推理 极速响应
AirX
GLM-4.5-AirX
轻量级 强性能 极速响应
FLASH
GLM-4.5-Flash
免费 高效 多功能
能力支持
深度思考
启用深度思考模式,提供更深层次的推理分析
流式输出
支持实时流式响应,提升用户交互体验
Function Call
强大的工具调用能力,支持多种外部工具集成
上下文缓存
智能缓存机制,优化长对话性能
结构化输出
支持JSON等结构化格式输出,便于系统集成
Benchmark
总览
衡量 AGI 的第一性原理,是在不损失原有能力的前提下融合更多通用智能能力,GLM-4.5 是我们对此理念的首次完整呈现。GLM-4.5 融合更多复杂推理、代码和智能体等多种通用能力并有幸取得技术突破,首次在单个模型中实现将推理、编码和 Agent能力原生融合,以满足 Agent 应用的复杂需求。 为综合衡量模型的通用能力,我们选择了最具有代表性的12个评测基准,包括MMLU Pro、AIME24、MATH 500、SciCode、GPQA 、HLE、LiveCodeBench、SWE-Bench、Terminal-bench、TAU-Bench、BFCL v3和BrowseComp。综合平均分,GLM-4.5 取得了全球模型第二、国产模型第一,开源模型第一。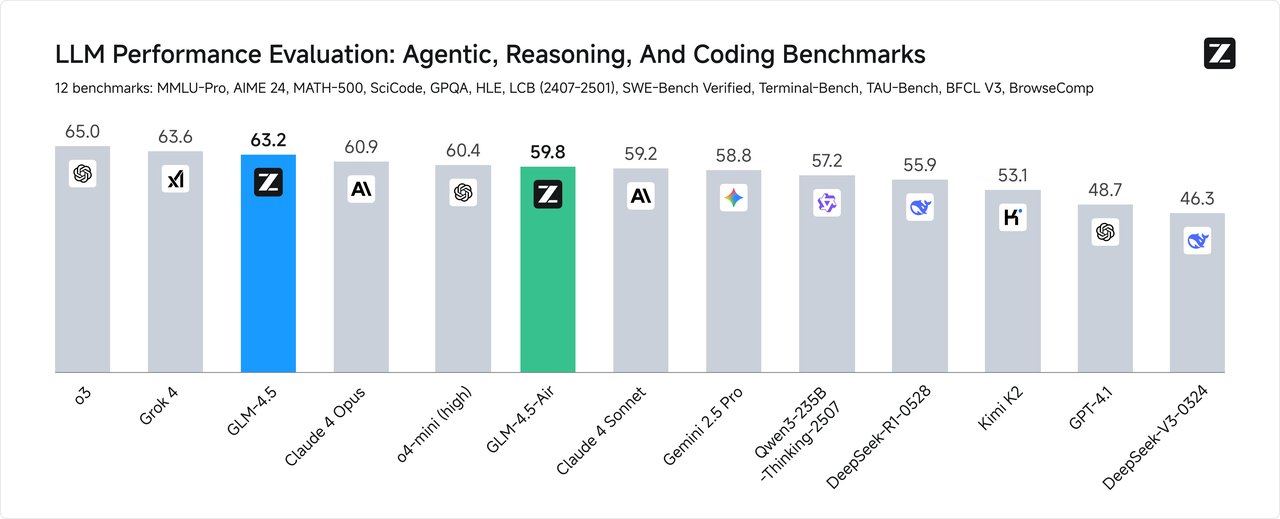
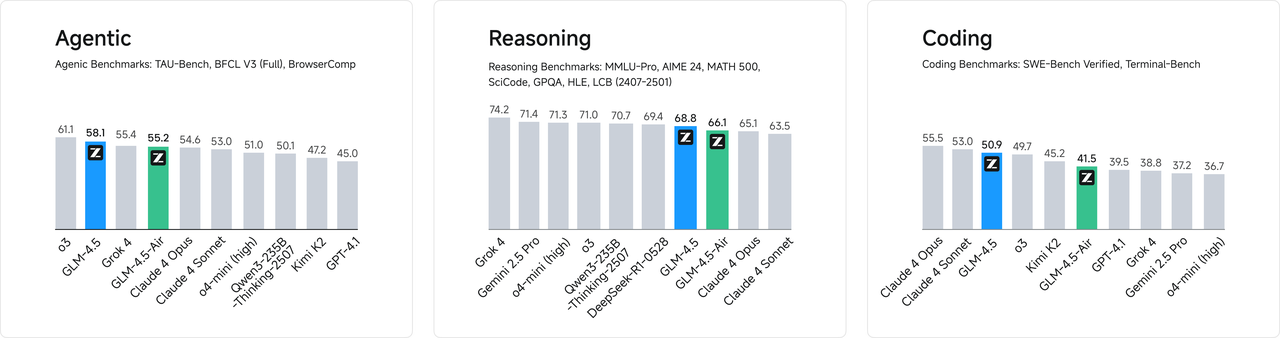
更高的参数效率
GLM-4.5 参数量为 DeepSeek-R1 的 1/2、Kimi-K2 的 1/3,但同样在多项标准基准测试中表现得更为出色,这得益于GLM模型的更高参数效率。值得注意的是,GLM-4.5-Air 以 106B 总参数 / 12B 激活参数实现了重要突破,在 Artificial Analysis 等推理基准上超越 Gemini 2.5 Flash、Qwen3-235B、Claude 4 Opus 等模型,性能位列国产前三。 在 SWE-Bench Verified 等图谱中,GLM-4.5 系列位于性能/参数比帕累托前沿,这表明在相同规模下,GLM-4.5 系列实现了最佳性能。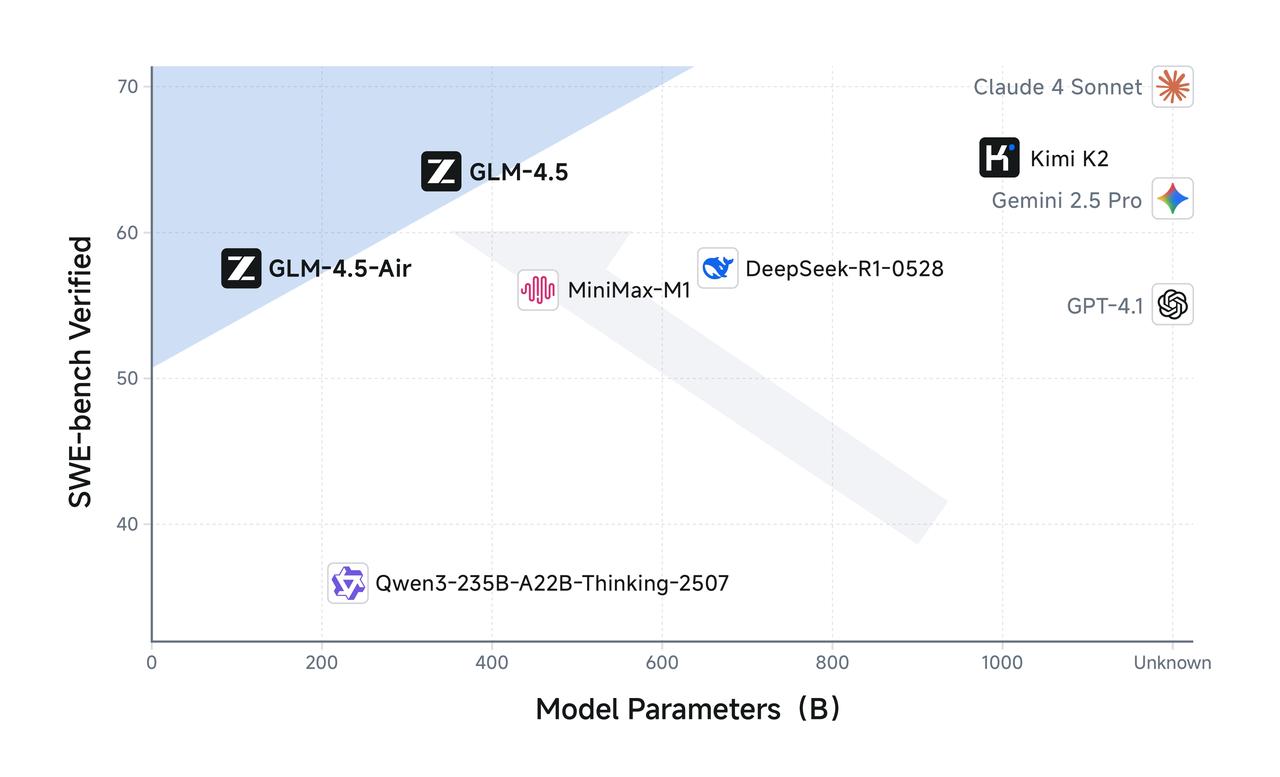
低成本、高速度
在性能优化之外,GLM-4.5 系列也在成本和效率上实现突破,由此带来远低于主流模型定价:API 调用价格低至输入 0.8 元/百万 tokens,输出 2 元/百万 tokens 同时,高速版本实测生成速度超过 100 tokens/秒,支持低延迟、高并发的实际部署需求,兼顾成本效益与交互体验。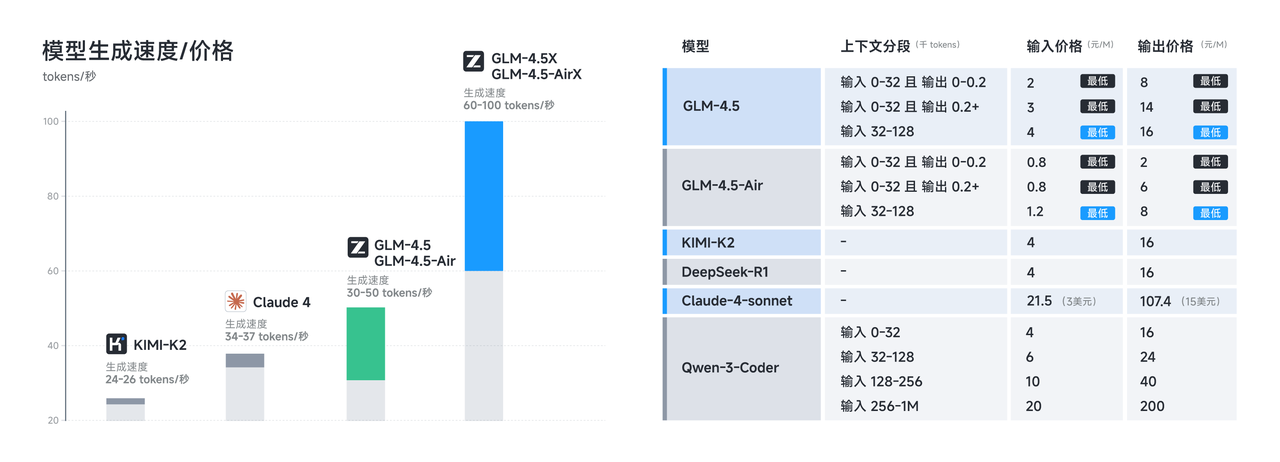
真实体验
真实场景表现比榜单更重要。为了评测GLM-4.5在真实场景Agent Coding中的效果,我们接入Claude Code与Claude-4-Sonnet、Kimi-K2、Qwen3-Coder进行对比测试。测试采用52个编程开发任务,涵盖六大开发领域,在独立容器环境中进行多轮交互测试。 实测结果显示(如下图),GLM-4.5相对其他开源模型展现出强劲竞争优势,特别在工具调用可靠性和任务完成度方面表现突出。GLM-4.5相比Claude-4-Sonnet仍有提升空间,在大部分场景中可以实现平替的效果。为确保评测透明度,我们公布了52道题目及Agent轨迹,供业界验证复现。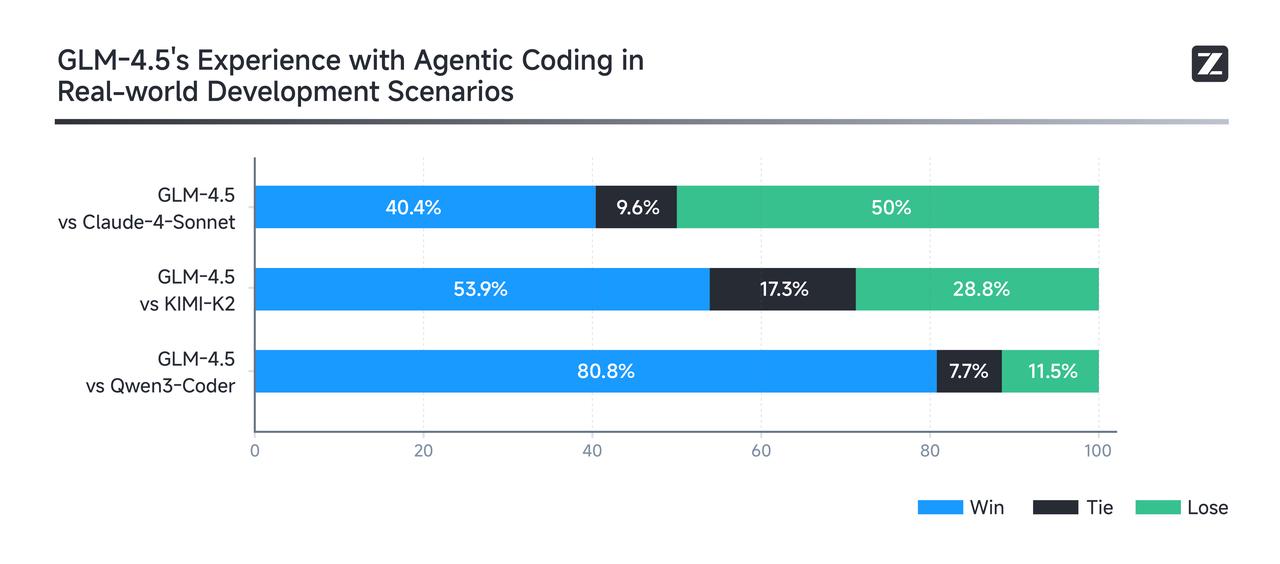
推荐场景
Tips:
- 点击“体验一下”会跳转至体验中心,建议先看完使用指南再体验哦~
- 体验过程会消耗模型tokens,如遇体验失败,可通过 链接 抢购特价资源包。
核心能力:代码能力——>智能代码生成|实时代码补全|自动化Bug 修复
- 覆盖Python、JavaScript、Java 等主流语言
- 基于自然语言指令生成结构清晰、可扩展的高质量代码
- 聚焦真实开发需求,避免模板化输出
使用资源
体验中心:快速测试模型在业务场景上的效果接口文档:API调用方式
调用示例
思考模式
GLM 4.5 提供了“深度思考模式”,用户可以通过设置thinking.type 参数来启用或关闭该模式。该参数支持两种取值:enabled(动态)和 disabled (禁用)。默认情况下开启动态思考功能。
- 简单任务(无需思考):对于不需要复杂推理的简单请求(例如事实检索或分类),无需思考。
- 智谱 AI 的成立时间。
- 翻译 I love you 这句英语成中文。
- 中等任务(默认/需要一定程度的思考):许多常见请求都需要一定程度的分步处理或更深入的理解。GLM-4.5系列模型可以灵活运用思考能力来处理以下任务。
- 为什么木星拥有较多的卫星,而土星却比木星的卫星少得多?
- 从北京去上海,对比乘坐飞机和动车的优劣势。
- 困难任务(最大思维能力):对于真正复杂的挑战,例如解决复杂的数学问题,联网问题,编码问题,这类任务要求模型充分发挥推理和规划能力,通常需要经过许多内部步骤才能提供答案。
- 详细解释 MoE 模型中不同专家是如何配合的。
- 根据上证指数的近一周的波动情况和时政信息,预测我是否应该购入股票指数ETF,为什么?
示例代码
以下是一个完整的调用示例,帮助您快速上手 GLM-4.5 模型。安装 SDK验证安装调用示例