概览
GLM-4.7-Flash 作为 30B 级 SOTA 模型,提供了一个兼顾性能与效率的新选择。面向 Agentic Coding 场景强化了编码能力、长程任务规划与工具协同,并在多个公开基准的当期榜单中取得同尺寸开源模型中的出色表现。在执行复杂智能体任务,在工具调用时指令遵循更强,Artifacts 与 Agentic Coding 的前端美感和长程任务完成效率进一步提升。输入模态
文本
输出模态
文本
上下文窗口
200K
最大输出 Tokens
128K
能力支持
思考模式
提供多种思考模式,覆盖不同任务需求
流式输出
支持实时流式响应,提升用户交互体验
Function Call
强大的工具调用能力,支持多种外部工具集成
上下文缓存
智能缓存机制,优化长对话性能
结构化输出
支持 JSON 等结构化格式输出,便于系统集成
MCP
可灵活调用外部 MCP 工具与数据源,扩展应用场景
推荐场景
Agentic Coding
Agentic Coding
GLM-4.7 面向「任务完成」而非单点代码生成,能够从目标描述出发,自主完成需求理解、方案拆解与多技术栈整合。在包含前后端联动、实时交互与外设调用的复杂场景中,可直接生成结构完整、可运行的代码框架,显著减少人工拼装与反复调试成本,适合复杂 Demo、原型验证与自动化开发流程。
多模态交互与实时应用开发
多模态交互与实时应用开发
在需要摄像头、实时输入与交互控制的场景中,GLM-4.7 展现出更强的系统级理解能力。能够将视觉识别、逻辑控制与应用代码整合为统一方案,支持如手势控制、实时反馈等交互式应用的快速构建,加速从想法到可运行应用的落地过程。
前端视觉审美优化
前端视觉审美优化
对视觉代码与 UI 规范的理解显著增强。GLM-4.7 能在布局结构、配色和谐度与组件样式上给出更具美感且一致的默认方案,减少样式反复“微调”的时间成本,适合低代码平台、AI 前端生成工具及快速原型设计场景。
高质量对话与复杂问题协作
高质量对话与复杂问题协作
在多轮对话中更稳定地保持上下文与约束条件,对简单问题回应更直接,对复杂问题能够持续澄清目标并推进解决路径。GLM-4.7 更像一名可协作的“问题解决型伙伴”,适用于开发支持、方案讨论与决策辅助等高频协作场景。
沉浸式写作与角色驱动创作
沉浸式写作与角色驱动创作
文字表达更细腻、更具画面感,能够通过气味、声音、光影等感官细节构建氛围。在角色扮演与叙事创作中,对世界观与人设的遵循更加稳定,剧情推进自然有张力,适合互动叙事、IP 内容创作与角色型应用。
专业级 PPT / 海报生成
专业级 PPT / 海报生成
在办公创作中,GLM-4.7 的版式遵循与审美稳定性明显提升。能够稳定适配 16:9 等主流比例,在字体层级、留白与配色上减少模板感,生成结果更接近“即用级”,适合 AI 演示工具、企业办公系统与自动化内容生成场景。
智能搜索与 Deep Research
智能搜索与 Deep Research
强化用户意图理解、信息检索与结果融合能力。在复杂问题与研究型任务中,GLM-4.7 不仅返回信息,还能进行结构化整理与跨来源整合,通过多轮交互持续逼近核心结论,适合深度研究与决策支持场景。
详细介绍
小而强的 Coding Agent
GLM-4.7 系列在编程、推理与智能体三个维度实现了显著突破: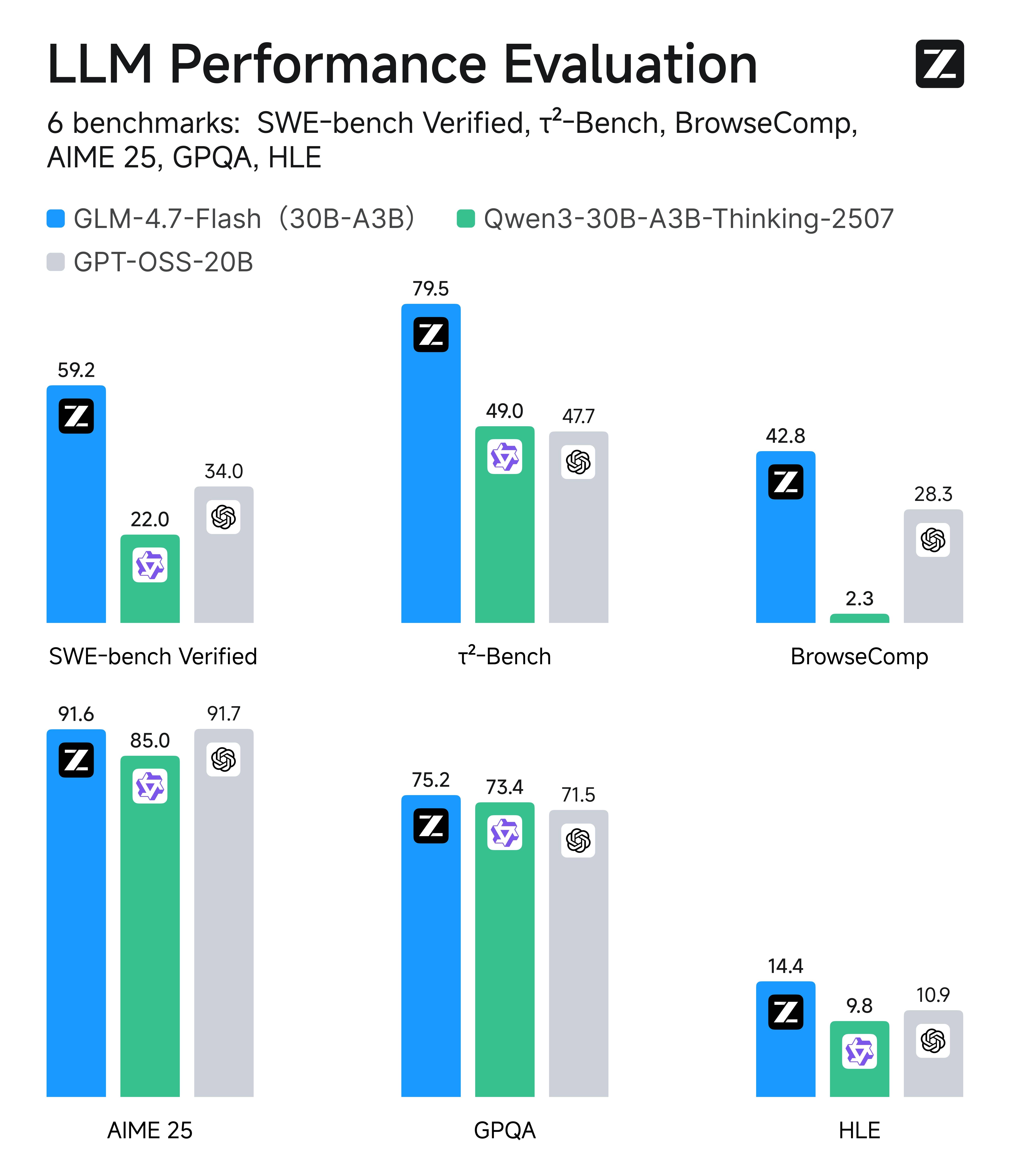
- 更强的编程能力:显著提升了模型在多语言编码和在终端智能体中的效果;现在可以在 Claude Code、Kilo Code、TRAE、Cline 和 Roo Code 等编程框架中实现“先思考、再行动”的机制,在复杂任务上有更稳定的表现
- 前端审美提升:GLM-4.7 系列模型在前端生成质量方面明显进步,能够生成观感更佳的网页、PPT 、海报
- 工具调用与协同执行更强: 增强对复杂链路的任务拆解与流程编排能力,可在多步执行中持续校验与纠偏,更适合端到端交付类的智能体任务。
- 通用能力增强:GLM-4.7 系列模型的对话更简洁智能且富有人情味,写作与角色扮演更具文采与沉浸感
使用资源
体验中心
快速测试模型在业务场景上的效果
接口文档
API 调用方式
调用示例
以下是完整的调用示例,帮助您快速上手 GLM-4.7-Flash 模型。- cURL
- Python
- Java
- Python(旧)
基础调用流式调用