概览
GLM-OCR 是一款轻量级的专业 OCR 模型,参数仅为0.9B,但多项能力达到了SOTA水平,以 “小尺寸、高精度” 实现文档解析能力新标杆。其核心要点如下:- 性能 SOTA:在模型发布时以 94.62 分登顶 OmniDocBench V1.5,并在表格、公式等多项主流文档理解基准中取得当前最佳表现;
- 针对真实业务场景优化:在代码文档、复杂表格、印章等复杂场景中表现稳定且精度领先,即使在版式复杂、字体多样或图文混排情况下,识别准确度依旧出色;
- 高效高性价比:仅 0.9B 参数规模,支持 VLLM 和 SGLang 部署,显著降低推理延迟与算力开销,成本约为传统 OCR 方案的 1/10。
输入模态
- PDF、图片(JPG、PNG)
- 单图 ≤ 10 MB,PDF ≤ 50 MB
- 最大支持 100 页
输出模态
文本、图片链接、md 文档
支持的语言
中文、英文、法语、西班牙语、俄罗斯语、德语、日语、韩语等……
能力支持
结构化输出
返回符合预定义格式的 JSON 数据
文档解析
高精度的文档信息识别能力
推荐场景
通用文本识别
通用文本识别
GLM-OCR 支持照片、截图、扫描件、文档输入,能够识别手写体、印章、代码等特殊文字,可广泛应用于教育、科研、办公等场景。
复杂表格解析
复杂表格解析
针对合并单元格、多层表头等复杂结构,模型能精准理解并直接输出 HTML 代码。无需二次制表,识别结果即可用于网页展示或数据处理,大幅提升表格录入与转换效率。
信息结构化提取
信息结构化提取
GLM-OCR 可从各类卡证、票据、表格中智能提取关键字段,并输出标准的 JSON 格式,无缝对接银行、保险、政务及物流等行业系统。
批量处理与RAG支持
批量处理与RAG支持
GLM-OCR 支持大批量文档的识别与解析,其高精度的识别能力和规整的输出格式,可为检索增强生成(RAG)提供坚实基础。
详细介绍
性能SOTA、精准干活儿
得益于自研 CogViT 视觉编码器与深度场景优化,GLM-OCR 实现了“小尺寸,高精度”。
GLM-OCR 参数量仅 0.9B,但模型发布时在权威文档解析榜单 OmniDocBench V1.5 中以 94.6 分取得SOTA。在文本、公式、表格识别及信息抽取四大细分领域的表现优于多款OCR专项模型,性能接近 Gemini-3-Pro 。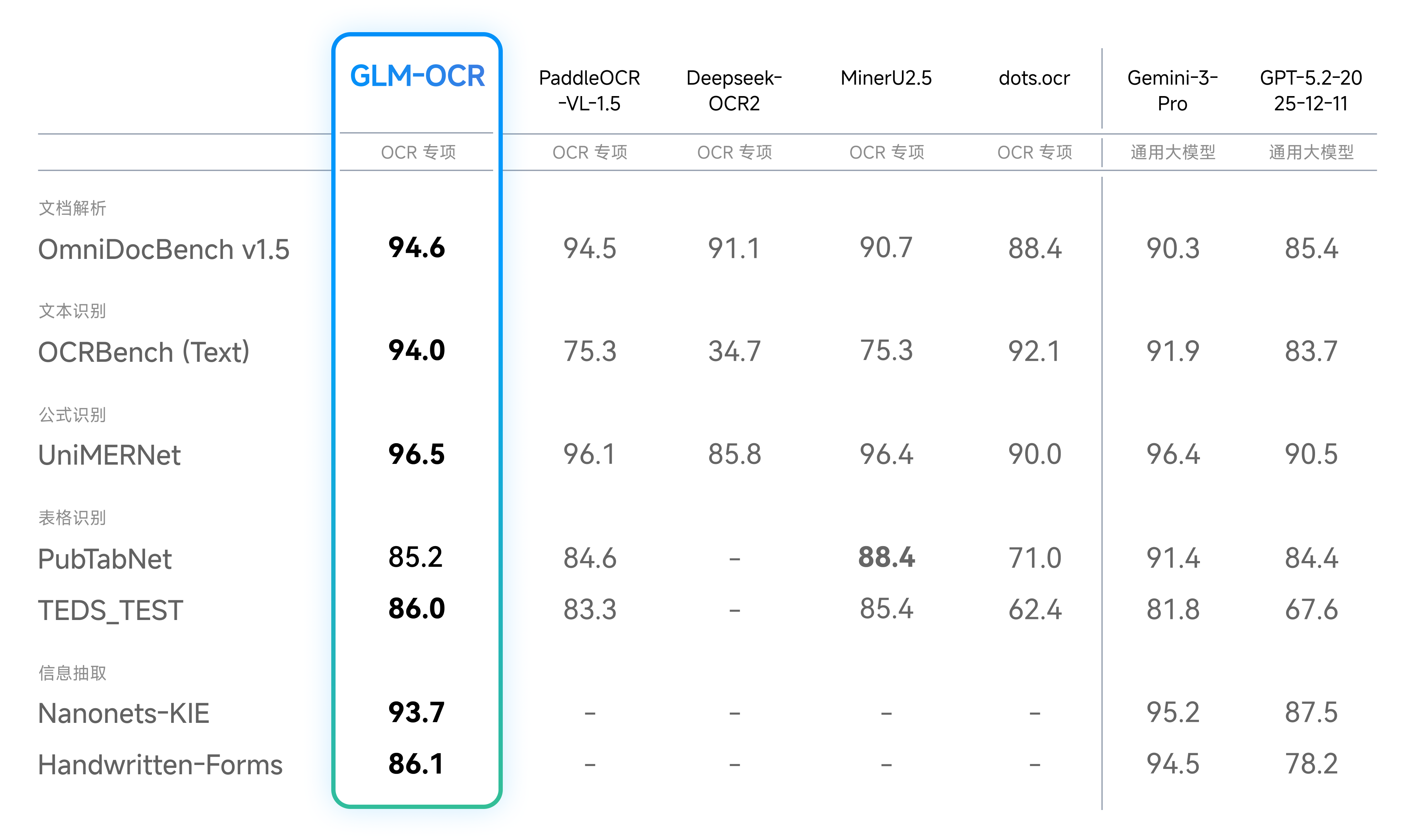 除了公开榜单,我们还针对真实业务中的六大核心场景进行了内部测评。结果显示,在模型发布时GLM-OCR 在代码文档、真实场景表格、手写体、多语言、印章识别、票据提取等维度均取得显著优势。
除了公开榜单,我们还针对真实业务中的六大核心场景进行了内部测评。结果显示,在模型发布时GLM-OCR 在代码文档、真实场景表格、手写体、多语言、印章识别、票据提取等维度均取得显著优势。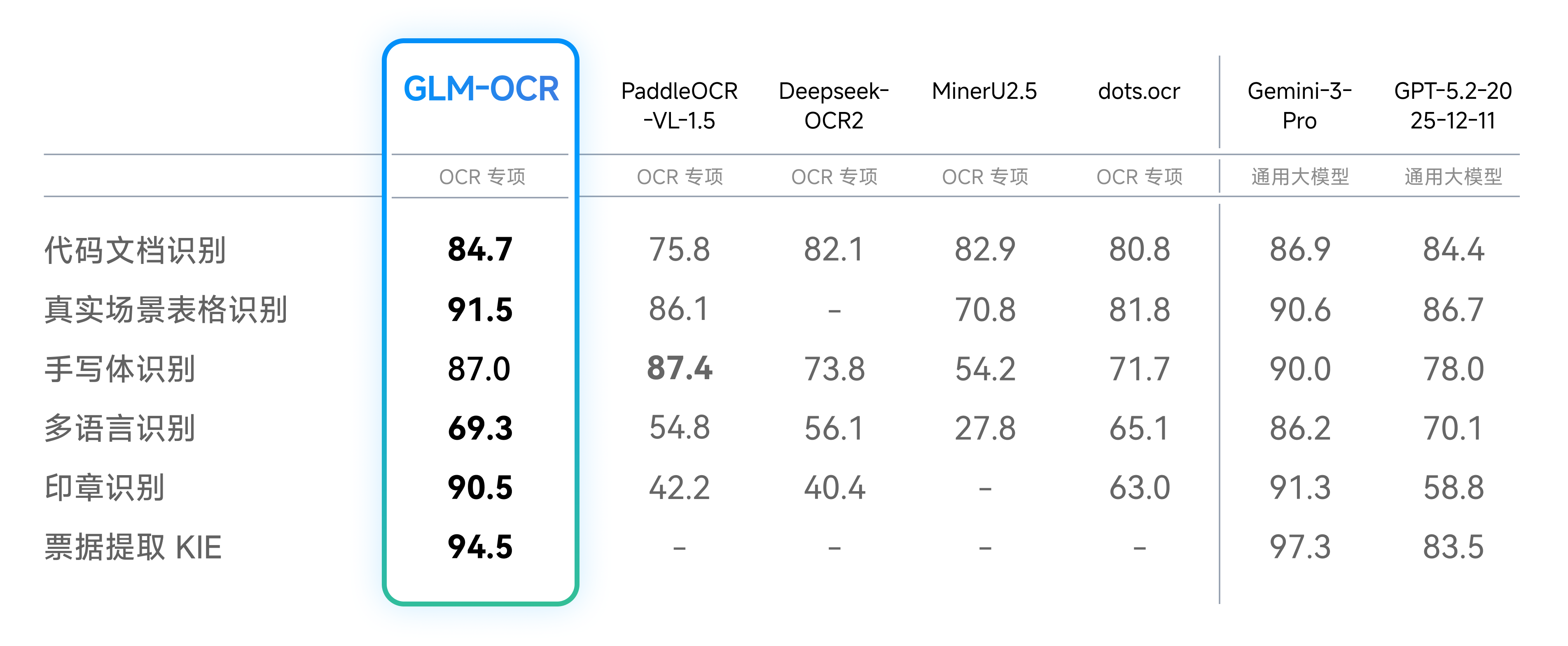
除了公开榜单,我们还针对真实业务中的六大核心场景进行了内部测评。结果显示,在模型发布时GLM-OCR 在代码文档、真实场景表格、手写体、多语言、印章识别、票据提取等维度均取得显著优势。更快、更便宜
速度方面,我们对比了在相同硬件环境与测试条件下(单副本,单并发),分别以图像文件和 PDF 文件为输入,不同 OCR 方法完成解析并导出 Markdown 文件的速度差异。结果显示,GLM-OCR 处理 PDF 文档的吞吐量达 1.86 页/秒,图片达 0.67 张/秒,速度显著优于同类模型。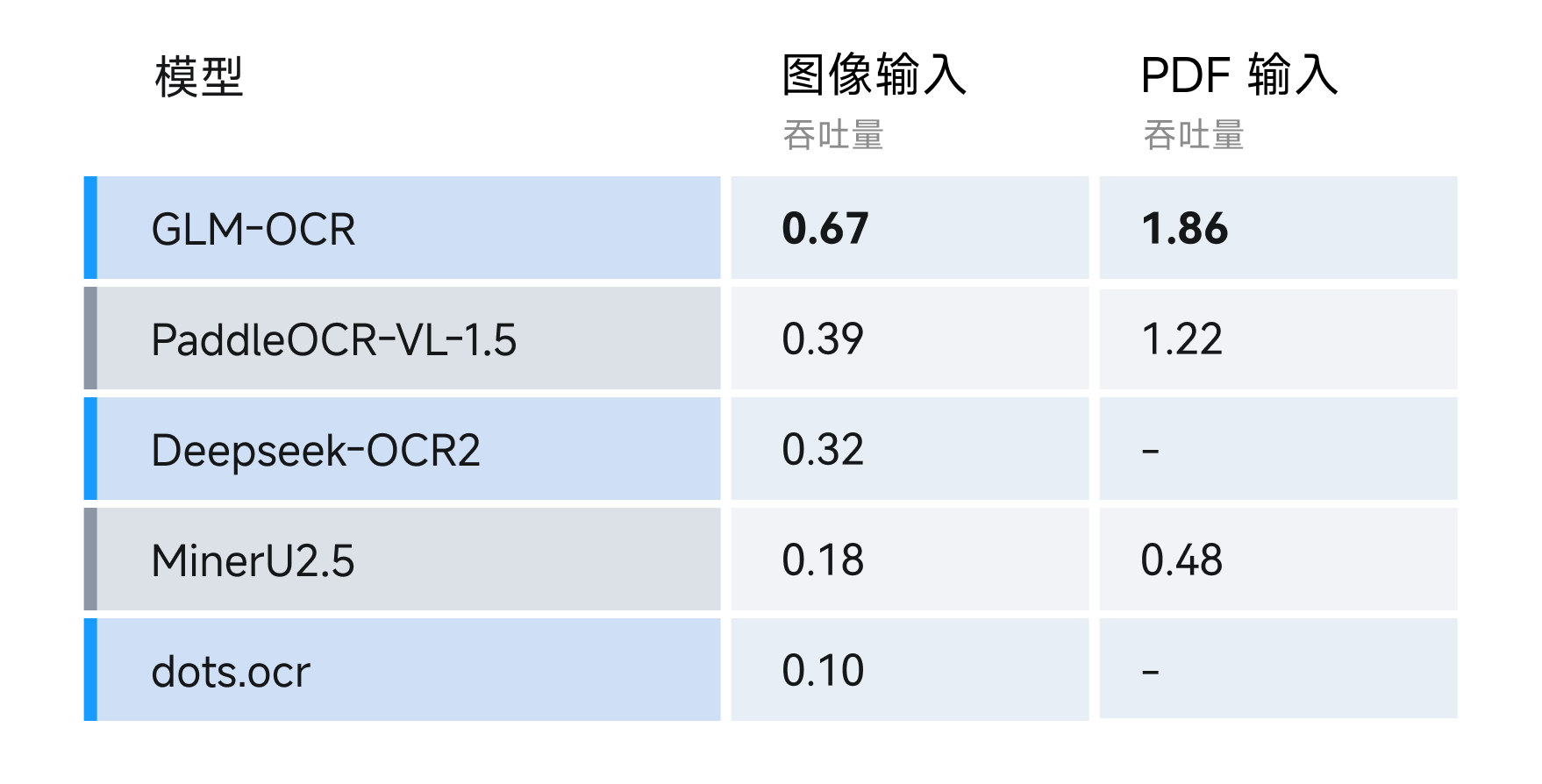 价格方面,API输入输出同价,仅需 0.2元/百万Tokens。1 元即可处理约 2000 张 A4 大小扫描图片或 200 份 10 页简单排版PDF,成本约为传统 OCR 方案的 1/10。
价格方面,API输入输出同价,仅需 0.2元/百万Tokens。1 元即可处理约 2000 张 A4 大小扫描图片或 200 份 10 页简单排版PDF,成本约为传统 OCR 方案的 1/10。
提示:实际性能受文件质量、网络及并发数影响,建议以实际接入测试为准。
想要更快? 推荐以下用法:
- 使用图片传入替代文件上传
- 多页 PDF 拆页并行调用
应用示例
- 手写字识别
- 表格识别
- 信息结构化提取
输入

输出
六国灭亡了,天下统一了,蜀地的山秃了,阿房宫建成了。 它覆盖三百多里地,遮蔽天日。阿房宫从骊山北边建起,折而向西,一直通向咸阳。


使用资源
体验中心
快速测试模型在业务场景上的效果
接口文档
API 调用方式
调用示例
以下是完整的调用示例,帮助您快速上手 GLM-OCR 模型。- cURL
- Python
- Java