概览
GLM-4.1V-Thinking 系列是 10B 尺寸性能卓越的视觉推理模型。它在图表/视频理解、前端 Coding、GUI 任务等核心能力达到全面新 SOTA,并引入思维链推理机制,显著提升模型在复杂场景中的回答精准度与可解释性。- GLM-4.1V-Thinking-FlashX
- GLM-4.1V-Thinking-Flash
定位
高并发版
价格
2 元 / 百万 Tokens
输入模态
视频、图像、文本
输出模态
文本
上下文窗口
64K
能力支持
内置深度思考
默认内置深度思考,提供更深层次的推理分析
视觉理解
强大的视觉理解能力,支持图片,视频,文件
流式输出
支持实时流式响应,提升用户交互体验
推荐场景
图文理解
图文理解
精准识别并综合分析图像与文本信息。
数学与科学推理
数学与科学推理
支持持复杂题解、多步演绎与公式理解。
视频理解
视频理解
具备时序分析与事件逻辑建模能力。
GUI 与网页智能体任务
GUI 与网页智能体任务
理解界面结构,辅助自动化操作。
视觉锚定与实体定位
视觉锚定与实体定位
语言与图像区域精准对齐,提升人机交互可控性。
使用资源
体验中心
快速测试模型在业务场景上的效果
接口文档
API 调用方式
详细介绍
多项视觉语言任务性能 SOTA
GLM-4.1V-Thinking 模型在高效部署的同时实现了性能突破。在 MMStar、MMMU-Pro、ChartQAPro、OSWorld 等 28 项权威评测中,以 23 项 10B 级模型优异成绩展现硬核实力,其中 18 项指标更是持平或超越 8 倍参数量的主流 VLM 模型,充分印证小体积模型的极限性能潜能。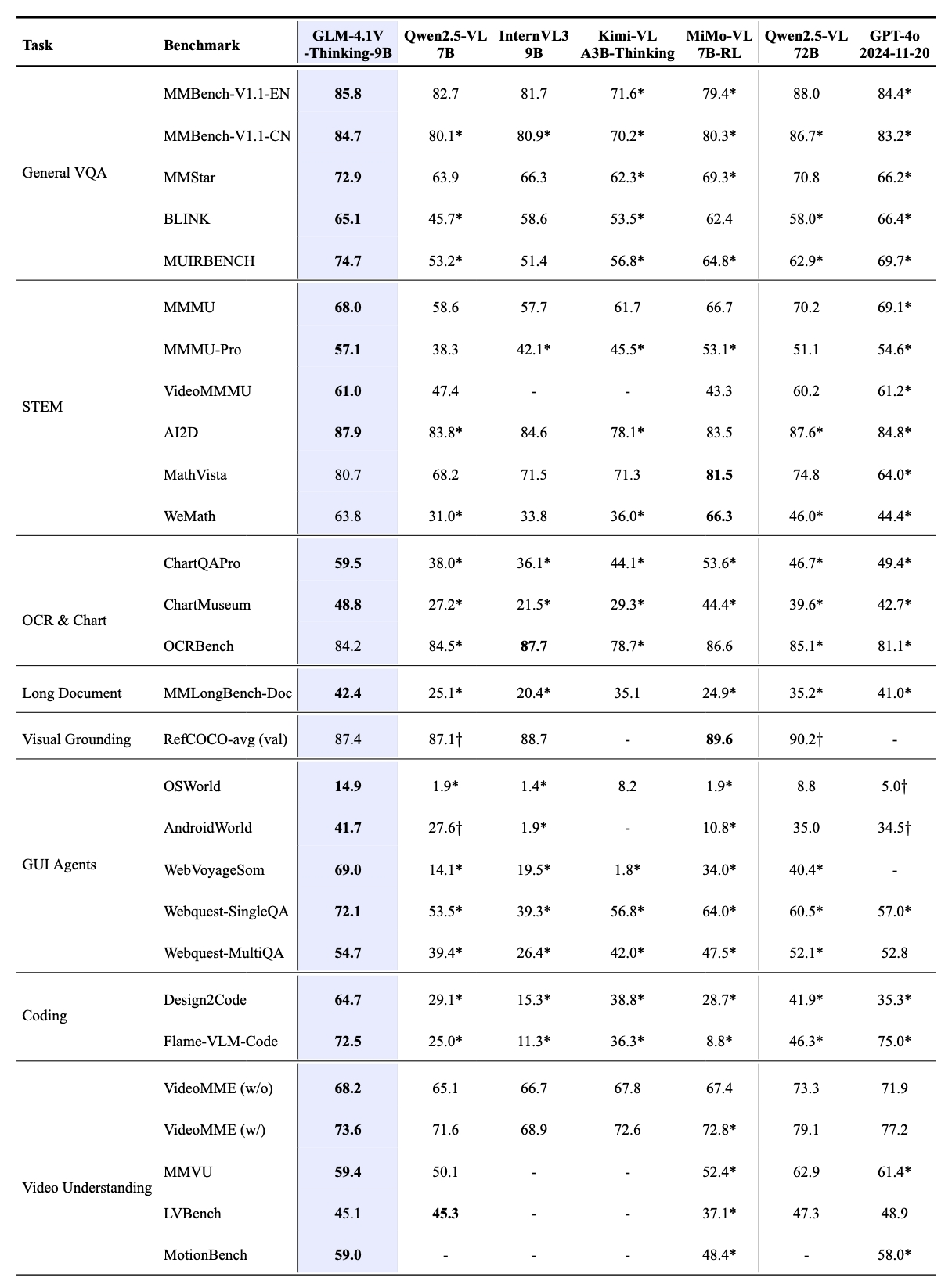 值得注意的是,模型在推荐场景任务处理中展现出卓越的适配能力,其高度的通用性与稳健性在复杂业务场景中尤为凸显。
值得注意的是,模型在推荐场景任务处理中展现出卓越的适配能力,其高度的通用性与稳健性在复杂业务场景中尤为凸显。
值得注意的是,模型在推荐场景任务处理中展现出卓越的适配能力,其高度的通用性与稳健性在复杂业务场景中尤为凸显。应用示例
- 图片问答
- 学科解题
- GUI Agent
- 前端网页Coding
输入
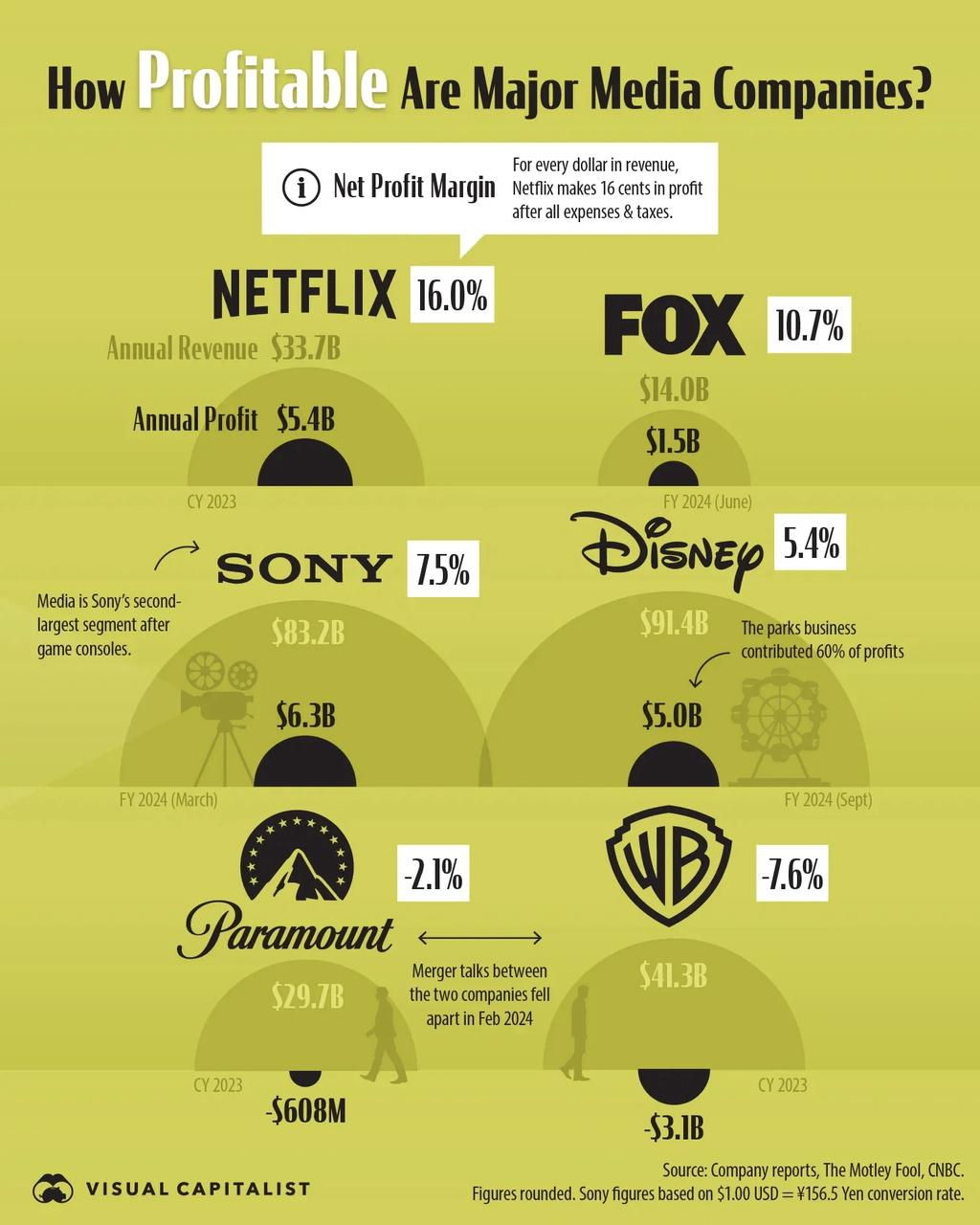
请找出这张图中年度利润最高的公司,以及该公司的最大部门?
输出
Sony has the highest annual profit at $6.3B. For Sony, the note states, “Media is Sony’s second - largest segment after game consoles.” Thus, the largest segment is game consoles.



调用示例
- Python
- Java
- Python(旧)
安装 SDK验证安装调用示例