概览
GLM-5.1 是智谱最新旗舰模型,代码能力大大增强,长程任务显著提升,能够在单次任务中持续、自主地工作长达 8 小时,完成从规划、执行到迭代优化的完整闭环,交付工程级成果。在综合能力与 Coding 能力上,GLM-5.1 整体表现对齐 Claude Opus 4.6,并在长程自主执行、复杂工程优化与真实开发场景中展现出更强的持续工作能力,是构建 Autonomous Agent 与长程 Coding Agent 的理想基座。
定位
旗舰基座模型
输入模态
文本
输出模态
文本
上下文窗口
200K
最大输出 Tokens
128K
能力支持
思考模式
提供多种思考模式,覆盖不同任务需求
流式输出
支持实时流式响应,提升用户交互体验
Function Call
强大的工具调用能力,支持多种外部工具集成
上下文缓存
智能缓存机制,优化长对话性能
结构化输出
支持 JSON 等结构化格式输出,便于系统集成
MCP
可灵活调用外部 MCP 工具与数据源,扩展应用场景
推荐场景
Agentic Coding
Agentic Coding
针对 Claude Code、OpenClaw 等典型 Agentic Coding 场景进一步优化,具备更强的长程规划、分步执行、过程调整与结果交付能力,在长程开发任务和复杂编程问题上的表现显著提升,适合多阶段、强依赖关系的真实工程任务。
通用对话
通用对话
在开放式问答、复杂指令理解与多轮交流场景中表现更稳,回复维度更丰富、内容更完整,具备更强的指令遵循能力与长上下文理解能力,适合高质量日常助手与复杂信息交互场景。
创意写作
创意写作
在文学化表达、情节延展、人物刻画与语言风格控制方面进一步增强,适用于小说片段、故事设定、文案创作等对表达力与一致性要求较高的写作任务。
Artifacts / 前端开发
Artifacts / 前端开发
适合网页、交互页面与前端原型生成场景,生成结果进一步减少模板感,视觉表达更多样,前端任务整体完成度更高,可更高效地支持从需求到可用产物的快速落地。
Office 生产力
Office 生产力
在 PPT、Word、PDF、Excel 等文档生产任务上整体提升,能够完成更复杂的内容组织、版式设计与结构化输出,默认审美与成品质量显著增强,适合长文档、报告、教材、论文等高强度生产场景。
详细介绍
综合与 Coding 能力:对齐全球顶尖水平
GLM-5.1 在综合能力与 Coding 能力上达到全球第一梯队,整体表现对齐 Claude Opus 4.6,并在多个关键评测中位居前列。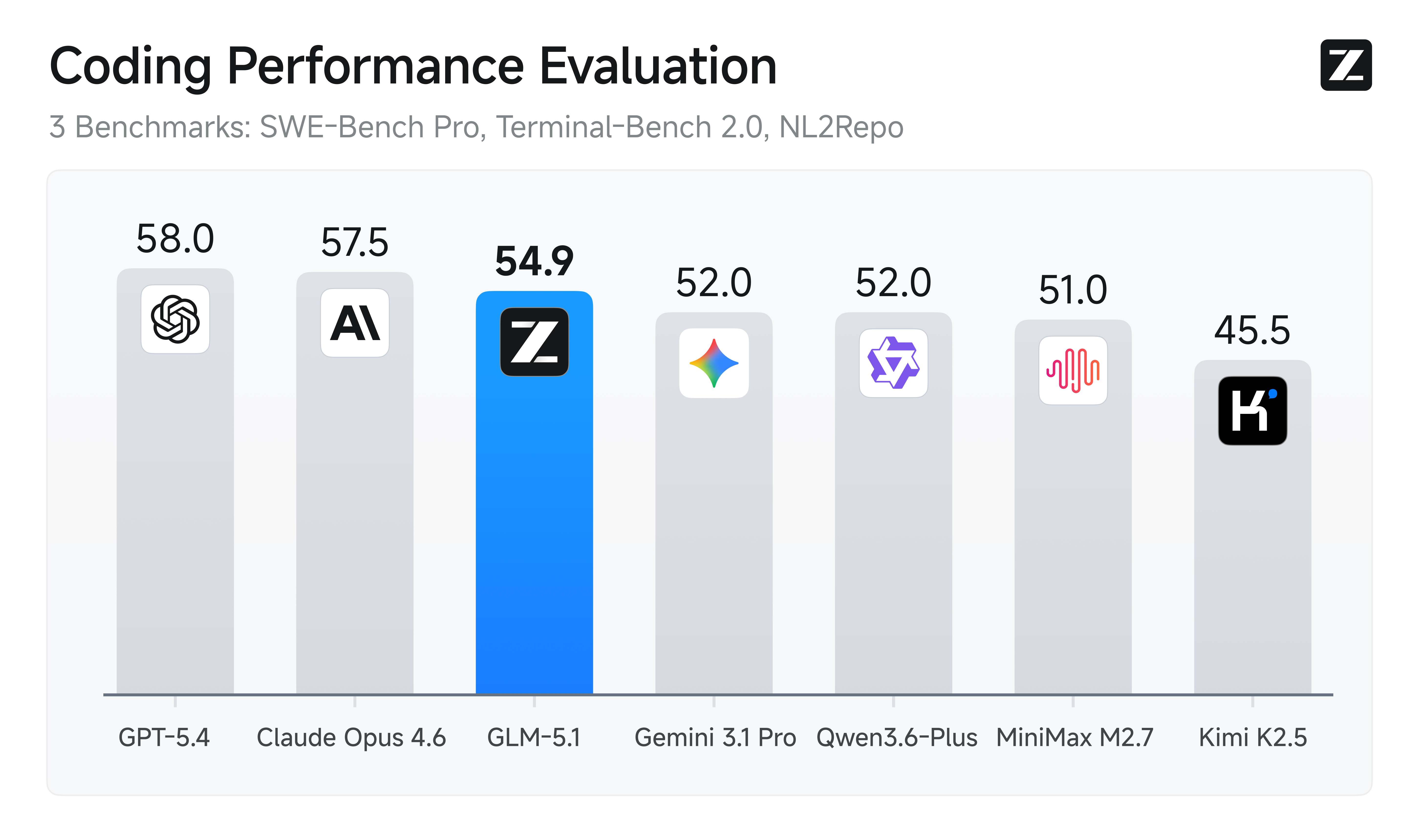 在 SWE-Bench Pro 基准测试中,GLM-5.1 取得 58.4 的成绩,超过 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro,刷新全球最佳表现。同时,在覆盖推理、编程、Agent、工具调用与浏览等 12 项代表性基准上,GLM-5.1 也展现出全面、均衡的能力结构。
在 SWE-Bench Pro 基准测试中,GLM-5.1 取得 58.4 的成绩,超过 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro,刷新全球最佳表现。同时,在覆盖推理、编程、Agent、工具调用与浏览等 12 项代表性基准上,GLM-5.1 也展现出全面、均衡的能力结构。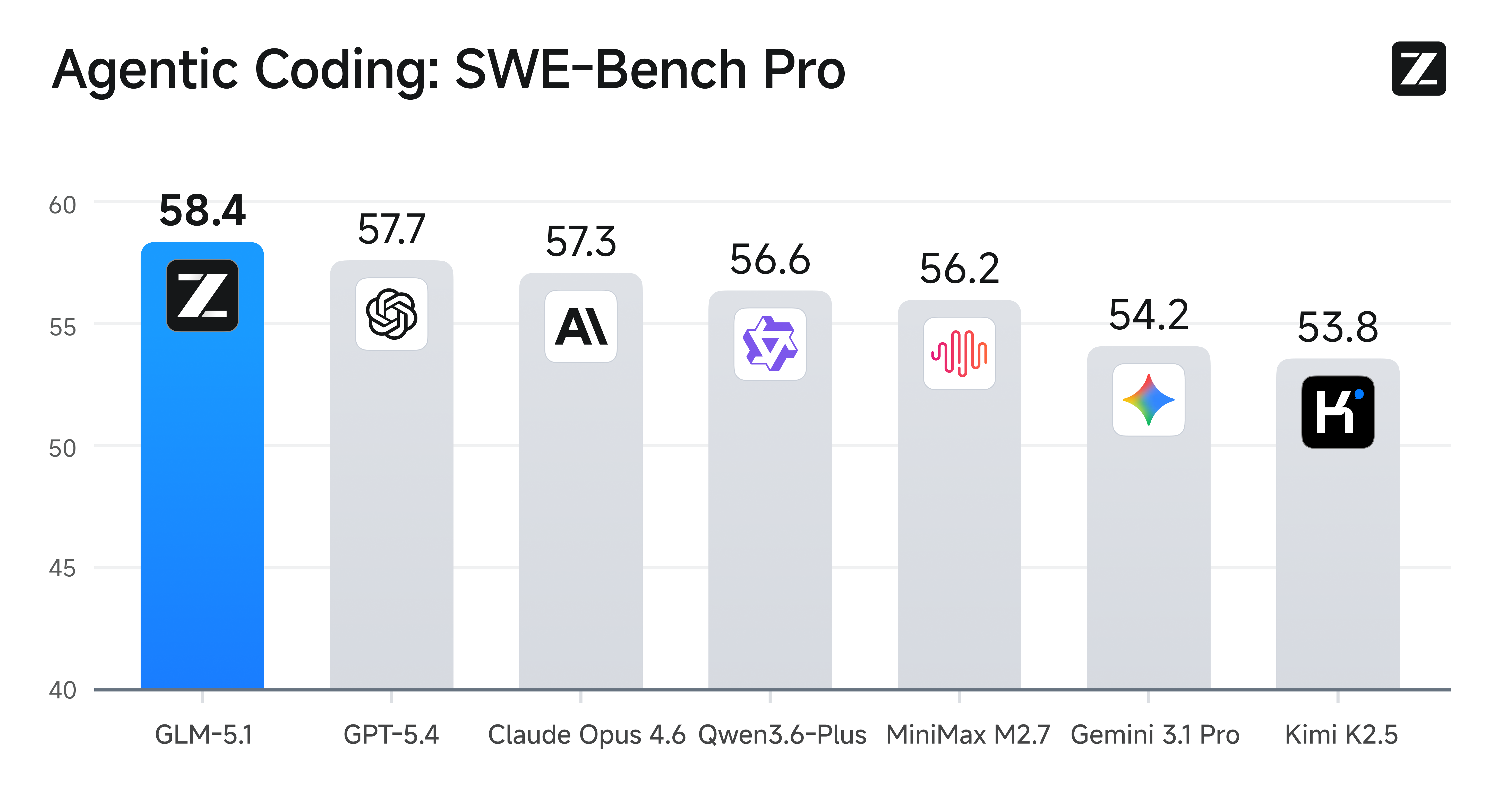 这表明 GLM-5.1 的提升并非单点突破,而是在通用智能、真实编程与复杂任务执行三个维度上同步增强,更适合作为通用 Agent 系统与工程生产场景的基础模型。
这表明 GLM-5.1 的提升并非单点突破,而是在通用智能、真实编程与复杂任务执行三个维度上同步增强,更适合作为通用 Agent 系统与工程生产场景的基础模型。
在 SWE-Bench Pro 基准测试中,GLM-5.1 取得 58.4 的成绩,超过 GPT-5.4、Claude Opus 4.6 和 Gemini 3.1 Pro,刷新全球最佳表现。同时,在覆盖推理、编程、Agent、工具调用与浏览等 12 项代表性基准上,GLM-5.1 也展现出全面、均衡的能力结构。这表明 GLM-5.1 的提升并非单点突破,而是在通用智能、真实编程与复杂任务执行三个维度上同步增强,更适合作为通用 Agent 系统与工程生产场景的基础模型。长程任务能力:迈向 8 小时级持续工作
GLM-5.1 长程任务(Long Horizon Task)显著提升,重点提升模型在复杂目标下的持续执行、闭环优化与工程交付能力。相较于以分钟级交互为主的模型,GLM-5.1 能在单次任务中持续、自主地工作长达 8 小时,完成从规划、执行、测试到修复和交付的完整流程。在同等评估标准下,GLM-5.1 是少数具备 8 小时级持续工作能力的模型之一,也是中国模型中率先达到这一水平的代表。模型能力的衡量标准,正在从“单轮更聪明”进一步演进为“长程任务中能稳定工作多久、交付什么”。这类能力并不只是更长上下文,而是要求模型在长时间执行中持续保持目标一致性,减少策略漂移、错误累积和无效试错,真正具备面向复杂工程任务的自主执行能力。
工程交付能力:从代码生成向全自治智能体进化
GLM-5.1 的核心突破之一,是在长程任务中形成“实验—分析—优化”的自主闭环,而不是停留在一次性代码生成层面。模型能够主动运行 benchmark、识别瓶颈、调整策略,并在多轮迭代中持续提升结果质量。在典型案例中,GLM-5.1 可在 8 小时内从零构建完整 Linux 桌面系统;自主进行 655 轮迭代,完成整条优化链路,让向量数据库的查询吞吐提升到初始正式版本的 6.9倍;在 KernelBench Level 3 优化基准上,完成千轮工具调用优化真实机器学习模型负载,实现 3.6 倍几何平均加速比,远超 torch.compile max-autotune 模式的 1.49 倍。这些结果说明,GLM-5.1 已具备在复杂工程环境中自主探索、持续改进和稳定交付的能力,能够胜任系统构建、性能优化与长程 Coding Agent 等更高价值任务。
使用资源
体验中心:快速测试模型在业务场景上的效果接口文档:API 调用方式
调用示例
以下是完整的调用示例,帮助您快速上手 GLM-5.1 模型。
- cURL
- Python
- Java
- Python(旧)
基础调用流式调用