概览
GLM-5.2 是面向长任务时代的旗舰模型。支持真正可用的 1M 上下文,实测可承载项目级工程上下文,长程任务执行更稳定、工程规范遵循更可靠,开发场景成功率进一步提升。一次任务即可完成“从需求到多端可部署产物”的完整开发链路。定位
旗舰基座模型
输入模态
文本
输出模态
文本
上下文窗口
1M
最大输出 Tokens
128K
能力支持
思考模式
提供多种思考模式,覆盖不同任务需求
流式输出
支持实时流式响应,提升用户交互体验
Function Call
强大的工具调用能力,支持多种外部工具集成
上下文缓存
智能缓存机制,优化长对话性能
结构化输出
支持 JSON 等结构化格式输出,便于系统集成
MCP
可灵活调用外部 MCP 工具与数据源,扩展应用场景
推荐场景
项目级工程接管:让模型一次读懂一整个工程
项目级工程接管:让模型一次读懂一整个工程
最能体现 GLM-5.2 代际差异的起手式。它能持续保留模块边界、架构约束、接口契约、目录结构和历史决策,长任务后半程的上下文断层感明显降低。对复杂项目来说,关键体验是:模型不只读得多,还能把前面形成的工程判断带到后续执行里。推荐体验方式:
选择一个真实业务仓库,最好包含后端、前端或客户端、配置、测试、文档和工程规范。先让模型做技术盘点:
请阅读当前项目,输出系统架构图谱、核心模块职责、关键接口契约、主要数据流、核心调用链、潜在技术债,以及后续改造时必须遵守的工程约束。
长程重构执行:把真实改造任务交给它跑到底
长程重构执行:把真实改造任务交给它跑到底
GLM-5.2 在跨文件、多步骤、长链路任务中更稳。它会先拆解目标、识别依赖和风险,再分阶段实现、验证和收口。适合测试模块解耦、接口迁移、目录治理、SDK 适配、跨语言重构等需要连续推进的任务。推荐体验方式:
选择一个中型改造任务,给清楚边界,开启 /goal 模式:
请在不改变业务逻辑、接口签名和运行结果的前提下,完成当前模块的解耦重构。先给出执行计划、影响范围、风险边界和验证方式,完成后运行必要测试并输出验证结果。
生产级规范压力测试:看它能否守住研发硬约束
生产级规范压力测试:看它能否守住研发硬约束
GLM-5.2 对工程规范的保持度更高,尤其是在长上下文和多轮执行中。它更能遵守代码风格、架构边界、依赖约束、构建流程、测试要求和提交边界,降低越界修改、无效依赖、跳过验证、擅自提交等风险。推荐体验方式:
把团队真实规范交给模型,例如 CLAUDE.md、Agent.md 中的 lint 规则、构建命令、测试要求、提交规范、禁止操作清单。然后给它一个真实修改任务:
请严格遵守当前仓库工程规范。不允许引入新依赖,不允许修改接口契约,不允许主动提交。修改完成后运行构建、lint 和测试,并说明验证结果和未覆盖风险。
移动端真机调试闭环:从代码实现到设备验证
移动端真机调试闭环:从代码实现到设备验证
GLM-5.2 在移动端场景中,能覆盖客户端架构、流式消息、长连接状态、本地状态管理、键盘行为、滚动逻辑、系统通知、权限机制和后台恢复。更关键的是,它能结合 ADB、logcat、截图和运行日志定位真机问题,真正贴近移动端工程开发实践。推荐体验方式:
选择一个真实 Android 或小程序任务,让模型从实现走到验证:
请用 Kotlin 实现一个原生 Android 客户端,对接现有服务端 API,支持多会话、流式消息、语音输入、通知和断线重连。完成后使用 ADB 安装到真机,并结合 logcat 和截图完成调试。
微信小程序开发:从 Web 应用迁移到微信小程序
微信小程序开发:从 Web 应用迁移到微信小程序
GLM-5.2 能处理小程序开发中的页面分包(subpackages)、自定义组件、页面级组件、页面栈管理、wx.request 封装与接口层适配、鉴权与登录态维护(wx.login + 自定义登录态)、应用/页面/组件三级生命周期管理和异常状态。适合测试模型是否能把已有 Web 页面、官网或后台能力,重新组织成符合小程序平台规范的可运行工程。推荐体验方式:
选择一个已有 Web 项目,指定目标技术栈(原生小程序 / Taro / uni-app),将 Web 项目所有功能迁移成小程序版本:
请将当前 Web 项目的所有功能迁移为微信小程序。要求使用 [原生/Taro/uni-app] 技术栈。先分析页面结构、核心用户路径、后端接口契约和平台限制(包体积上限、域名白名单、HTTPS要求),再完成页面、组件、页面跳转和数据流实现。完成后说明运行方式、已接入接口、未覆盖功能和后续优化点。
小游戏开发:从玩法规则到可玩闭环
小游戏开发:从玩法规则到可玩闭环
GLM-5.2 适合测试小游戏中的规则理解、状态机设计、关卡结构、计分逻辑、资源加载、交互反馈和结算流程。相比静态页面,这类任务更能体现模型对复杂状态、用户路径和产品完成度的理解。推荐体验方式:
给一个完整但不过度详细的玩法目标,让模型先设计规则,再实现可运行版本:
请开发一个轻量闯关小游戏。先设计核心玩法循环、状态机、关卡结构、计分规则、失败与结算逻辑,再实现开始、暂停、继续、结算、重新开始和本地存档等基础功能。完成后说明项目结构、已验证功能和下一步扩展方向。
科研复刻:从论文数据到可运行工程
科研复刻:从论文数据到可运行工程
GLM-5.2 能把论文里的模型架构、损失函数、数据管线与训练/推理脚本,从零写成可运行、与论文一致的代码。它一次就能搭对模型结构、在多文件间保持规则一致,并自主跑通、自主修复代码与环境问题——交付的是真正能复现论文指标的工程,而非片段。推荐体验方式:
挑一篇带模型与实验的论文(作者开源代码或公开指标更佳),把论文和数据交给它,看它能否自己把模型写出来、跑通并对齐论文指标:
请依据这篇论文与数据复现实验。补全论文未写明的实现细节,用 PyTorch 搭建模型结构与损失函数、构建数据管线和训练/推理脚本,确保能跑通、多文件间一致。自主定位并修复运行中的问题,逐项核对论文指标直至对齐,并说明复现路径、关键改动与未对齐项。
代码生成视频闭环:从自然语言创意到可演示成片
代码生成视频闭环:从自然语言创意到可演示成片
GLM-5.2 在 Coding to Video 场景中,能够基于 Remotion 框架——用 React 代码(组件、参数、动画逻辑)“编程式”地制作视频、再渲染成 mp4,简单说就是”把视频当代码写”——覆盖自然语言创意转译、Remotion React 代码生成、视频渲染输出等完整能力,通过代码驱动生成一段可运行、可演示的完整视频。推荐体验方式:
选择一个真实的视频创意任务,让模型从一句自然语言开始,逐步完成可渲染、可播放、可迭代的视频作品:
请用 Remotion 新建一个 composition,加入一张地图,从洛杉矶(LA)拉远镜头但始终保持聚焦在它身上。完成后绘制一条从洛杉矶到纽约(NY)的路线动画,并让相机跟随这条线移动。再给这趟旅程加一站,这次我们去巴黎。
详细介绍
1M 上下文:让长程任务稳定可用
长程任务的基础,不是拥有 1M 上下文,而是让 1M 上下文真正可用。GLM-5.2 实现了 Solid 1M 无损上下文,并针对长程 Coding Agent 场景进行了数月强化训练,覆盖大规模实现、自动化研究、性能优化等高价值任务。相比仅扩展上下文长度的方案,GLM-5.2 在超长上下文下保持更稳定的性能,在部分真实测试中甚至超过 Opus。(详见技术博客)1M 上下文支撑了 GLM-5.2 出色的长程交付能力。在 FrontierSWE、SWE-Marathon、PostTrainBench 等长程任务基准上,GLM-5.2 整体表现介于 Claude Opus 4.7 与 4.8 之间,是当前排名最高的开源模型。其中,在 FrontierSWE 上仅落后 Opus 4.8 约 1%,同时超过 GPT-5.5(1%)和 Opus 4.7(11%);在更具挑战性的 SWE-Marathon 上仍有提升空间,与 Opus 4.8 存在约 13% 的差距。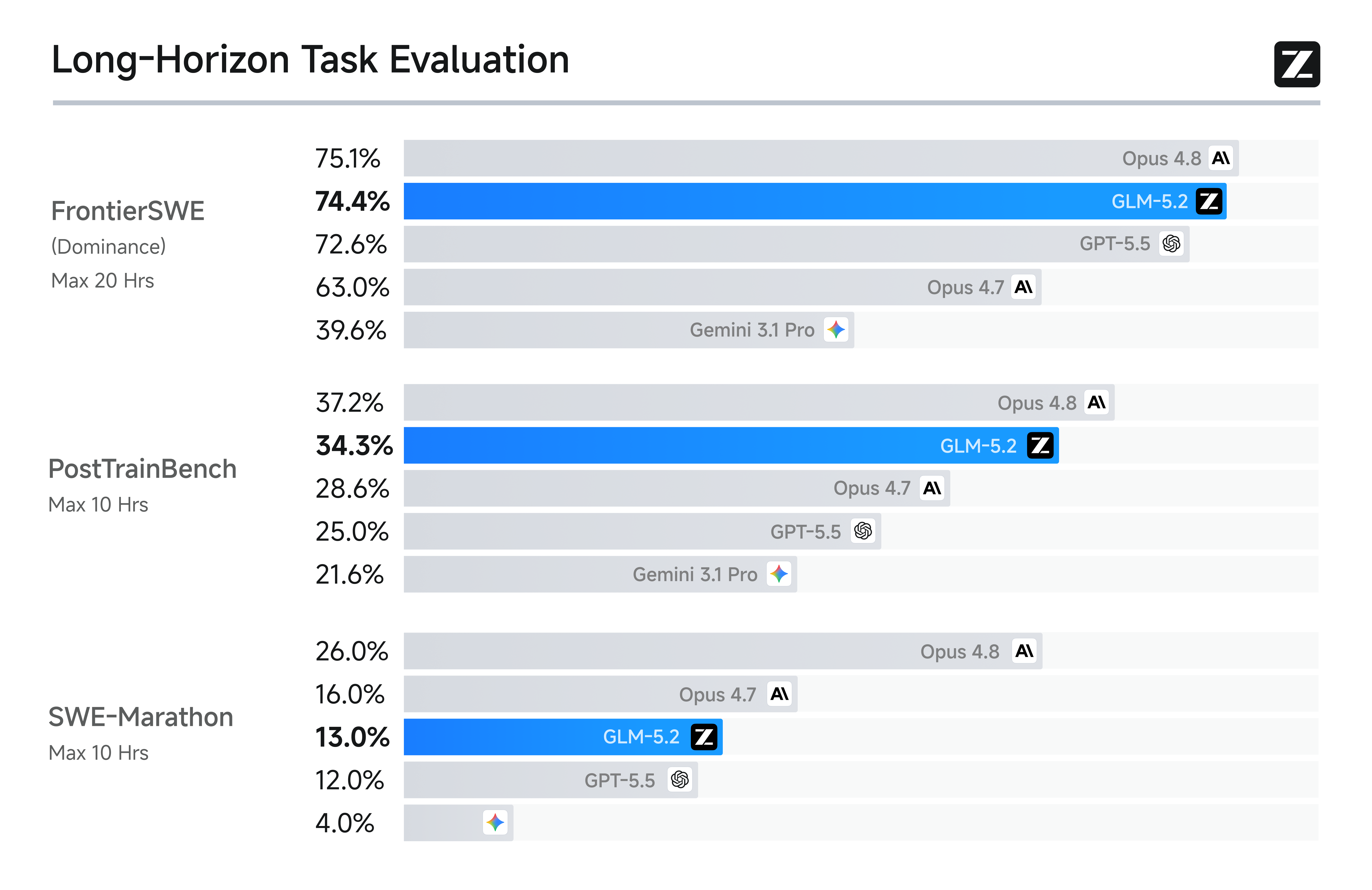 在实际体验中,GLM-5.2 可自主完成任务拆解、架构设计、前后端开发、测试修复与部署交付,最终生成可上线的 Web、移动端和小程序应用。整个流程累计处理超过 85 万(850K)tokens,接近用满 1M 上下文窗口。过去需要团队协作数周完成的工程,如今可在一次连续的长程任务中完成。
在实际体验中,GLM-5.2 可自主完成任务拆解、架构设计、前后端开发、测试修复与部署交付,最终生成可上线的 Web、移动端和小程序应用。整个流程累计处理超过 85 万(850K)tokens,接近用满 1M 上下文窗口。过去需要团队协作数周完成的工程,如今可在一次连续的长程任务中完成。
在实际体验中,GLM-5.2 可自主完成任务拆解、架构设计、前后端开发、测试修复与部署交付,最终生成可上线的 Web、移动端和小程序应用。整个流程累计处理超过 85 万(850K)tokens,接近用满 1M 上下文窗口。过去需要团队协作数周完成的工程,如今可在一次连续的长程任务中完成。榜单与开发者双重验证的 Coding 能力
GLM-5.2 在前端、后端、长程任务等开发场景下的成功率相比前一代GLM-5.1都有长足提升,复杂系统工程与深度调试更稳。在主流编程基准上,GLM-5.2 保持开源SOTA,与Claude Opus 4.8处于可比区间。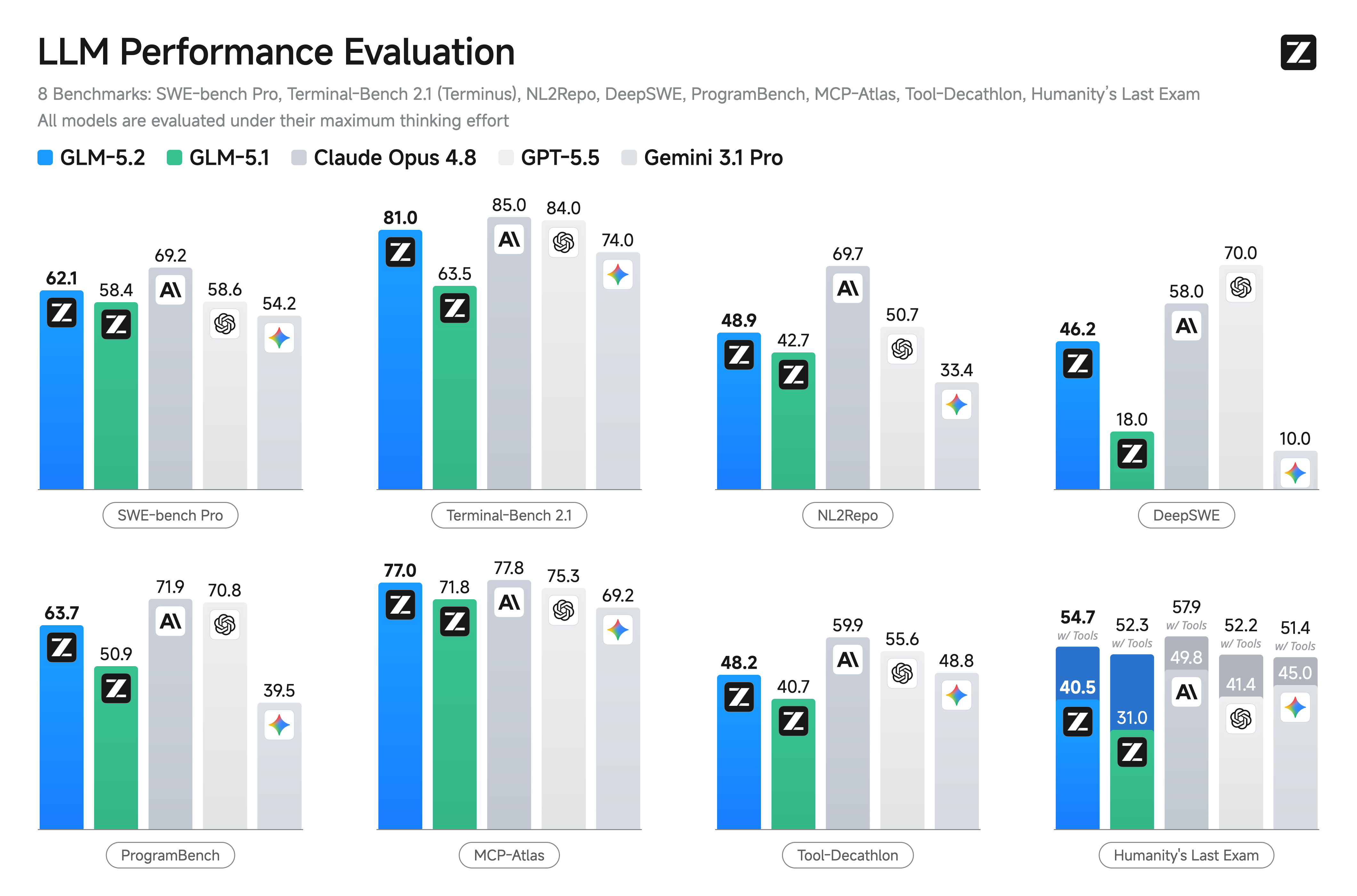 在全球百万用户参与盲测的前端开发评估系统Code Arena 上,GLM-5.2 取得全球可用模型第一的表现。
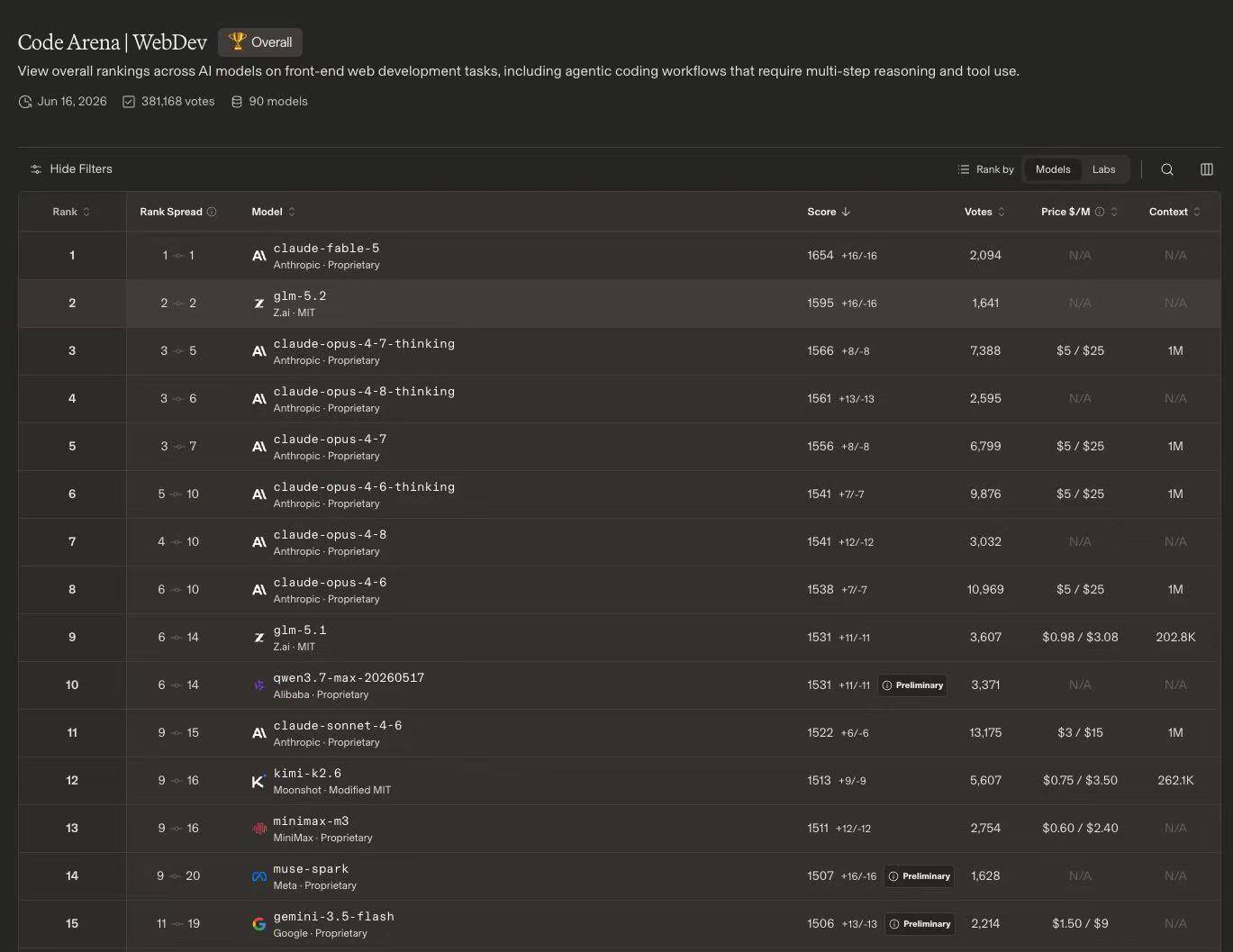
在全球百万用户参与盲测的前端开发评估系统Code Arena 上,GLM-5.2 取得全球可用模型第一的表现。
 发布前,GLM-5.2 已提前向 GLM Coding Plan 用户开放,开发者感知到的提升集中在以下几点:
发布前,GLM-5.2 已提前向 GLM Coding Plan 用户开放,开发者感知到的提升集中在以下几点:
在全球百万用户参与盲测的前端开发评估系统Code Arena 上,GLM-5.2 取得全球可用模型第一的表现。
发布前,GLM-5.2 已提前向 GLM Coding Plan 用户开放,开发者感知到的提升集中在以下几点:- 项目级上下文承载更强,能把完整工程放进同一条推理链路里
- 长程任务执行更稳定,复杂任务能持续推进,不容易中途跑偏
- 生产级工程规范遵循更可靠,能守住团队研发流程里的硬约束
- 客户端与移动端工程能力更扎实,不止写 App,还能完成真机调试闭环
使用资源
体验中心:快速测试模型在业务场景上的效果接口文档:API 调用方式
调用示例
以下是完整的调用示例,帮助您快速上手 GLM-5.2 模型。- cURL
- Python
- Java
- Python(旧)
基础调用流式调用